

一、惰性学习法与急切学习法
急切学习法:指在利用算法进行判断之前,先利用训练集数据通过训练得到一个目标函数,在需要进行判断时利用已经训练好的函数进行决策。
惰性学习法:在最开始的时候不会根据已有的样本创建目标函数,只是简单的把训练用的样本储存好,后期需要对新进入的样本进行判断的时候才开始分析新进入样本与已存在的训练样本之间的关系。
典型的惰性学习法是KNN,它不会根据训练集训练一个模型,而是将训练集存储起来,当需要预测的时候,从训练集中找到最相似的样本,把其结果作为预测结果。
二、KNN算法实现
假设训练数据集如下:
train_data = np.array([[700,500],[750,460],[1000,230],[800,420],[690,500],[730,490],[60,1200],[80,1100],[1260,200],[240,1200],[200,1090],[1200,200],[900,320],[97,1170],[118,1108],[1203,200],[1180,88],[1111,99],[67,1222]])
train_label = np.array(['多云','多云','晴','多云','多云','多云','雨','雨','晴','雨','雨','晴','晴','雨','雨','晴','晴','晴','雨'])
训练数据集有两列特征,标签为1列,有’多云‘,’晴‘,’雨‘三种情况。
测试数据如下:
test_data = [800,400]
距离度量方式采用的是欧式距离,代码如下:
def Euclidean_distance(x,y):
distance = 0
for i in range(0,len(x)):
distance = distance + x[i]**2 + y[i]**2
return distance ** 1/2
我们将K从1取到19(一共有19条数据),观察最后的结果: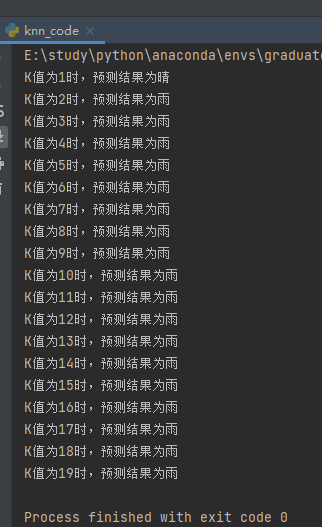
完整代码如下:
import numpy as np
def Euclidean_distance(x,y):
distance = 0
for i in range(0,len(x)):
distance = distance + x[i]**2 + y[i]**2
return distance ** 1/2
train_data = np.array([[700,500],[750,460],[1000,230],[800,420],[690,500],[730,490],[60,1200],[80,1100],[1260,200],[240,1200],[200,1090],[1200,200],[900,320],[97,1170],[118,1108],[1203,200],[1180,88],[1111,99],[67,1222]])
train_label = np.array(['多云','多云','晴','多云','多云','多云','雨','雨','晴','雨','雨','晴','晴','雨','雨','晴','晴','晴','雨'])
test_data = [800,400]
distance = []
for i in train_data:
distance.append(Euclidean_distance(i,test_data))
distance_new = sorted(distance,reverse=True)
for k in range(1,20):
num = 0
predict_label = []
for i in distance_new:
if num == k:
break
predict_label.append(train_label[distance.index(i)])
num = num + 1
print("K值为{k}时,预测结果为{weather}".format(k = k,weather = max(predict_label)))



评论(0)
您还未登录,请登录后发表或查看评论