

一、基本介绍
决策树是一种类似于流程图的树结构,其中每个内部节点表示在一个属性上的测试,每个分支代表该测试的一个输出,而每个叶子节点(终端节点)存放一个分类结果。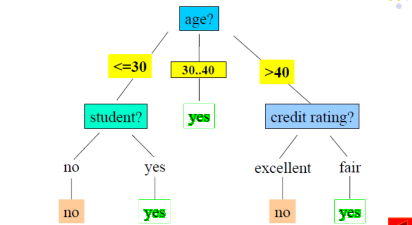
上图是一个决策时的示例。
当决策树构建好之后,对检验记录进行分类就很容易,从树的根节点开始,将测试条件用于检验记录,沿着树的分支达到叶子节点,得到分类结果。
二、决策树构建
原则上讲,对于给定的属性集,可以构造的决策树很多,所有如何在合理的时间内构造出具有一定准确率的决策树?通常都采用贪心算法,即在选择属性来划分数据时,采用一系列局部最优决策来构建决策树。
决策树构建过程必须要考虑两个问题
(1)选择哪一个属性来划分数据?即如何度量该属性对于划分之后的数据集的影响。
(2)停止划分的条件。
同时还要考虑属性的不同情况。
1.属性选择度量方法:
ID3/C4.5算法选择信息增益作为度量方法:原始的算法只适用于标称属性,改进后,可以在连续属性上使用。
CART算法选择Gini指数作为度量方法:原始的算法只适用于连续属性,改进后,可以在标称属性上使用。
信息熵:熵的定义如下: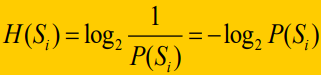
如果一件事情越确定,发生概率越大,信息熵越低。如果一件事情越不确定,发生概率小,信息熵越高。
整个信息空间的期望信息熵:
决策树算法ID3使用的属性度量是信息增益
信息增益定义为如下:
当类别标签有m个不同的值时,所以定义m个不同的类Ci(i = 1,2,…,m),D为数据集,设Ci,d是D中Ci类的元组的集合,|D|,|Ci,d|分别是D和Ci,d中元组的个数,则整个数据集D空间下的期望信息熵为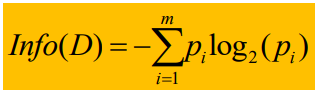
其中Pi = |Ci,d| / |D|,代表D中不同类别的概率。Info代表识别D中元组的类标号所需要的平均信息量,又称为D的信息熵。
假设用属性A的不同取值将D划分为D1,D2,…,Dv。
其中对于任意一个Dj,它的A属性值都为Aj,对于属性A划分之后的空间,对应的期望信息熵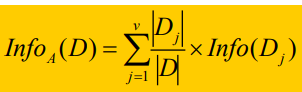
其中: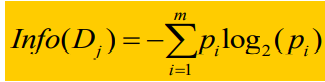
其中,|Dj|代表Dj元组的个数(既是属性A的值等于Aj的元组个数),|D|代表按照属性A划分的分支数。
Info(Dj)表示的是当属性A = Aj时,空间的期望信息熵。
我的理解如下:
整个数据集空间按照A的取值不同(Aj)被分为不同的Dj空间,对于每一个Dj空间,也有类别标签不同的情况。
所以当数据集空间D被划分之后,计算空间的期望信息熵分成两步,第一步针对每一个子空间Dj,计算Info(Dj),第二步根据每个子空间Dj的概率,求整个空间的期望。
所以信息增益代表着原来的信息熵与新的信息熵之间的差。
ID3算法会选择信息增益最大的属性作为划分属性,即是选择的划分属性A会使得划分之后的空间,熵值最小,也就是最稳定。
ID3算法的缺点:
(1)ID3算法会倾向于选择属性取值较多的属性,因为当属性取值较多时,划分之后的信息熵较小,对应的信息增益更大。
(2)ID3算法只能处理离散属性。
针对缺点1,C4.5算法做出了以下改进:
选择具有最大信息增益率的属性作为分裂属性,
增益率的公式如下: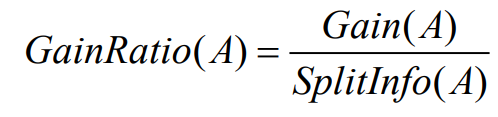
其中,Gain(A)与ID3算法的定义相同,
分裂信息SplitInfo(A)定义为:
针对缺点2:
将A的值递增排序,每对相邻值的中点被看做可能的分裂点,这样给定A的V个值,则需要计算V-1个可能的划分
对于A的每个可能分裂点,计算Info(D),其中分区个数为2,A具有最小期望信息需求的点选做A的分裂点。
CART算法选择Gini指数作为度量方法
Gini(T)定义如下: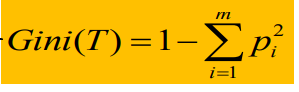
也可以看成在计算不纯度,其中Pi代表类别标签i的概率。
如果通过属性A将数据集划分成了大小分别为N1和N2的两个子集T1,T2。那么划分之后的GIni定义为:
选择具有最小 的属性作为划分属性。
的属性作为划分属性。
即是选择
最大的属性作为划分属性。
2.计算实例
题目: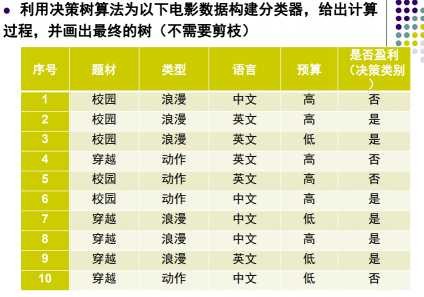
使用ID3算法构建决策树
计算Infor(D)以及每个属性对应的信息熵,
然后选择信息增益最大的属性作为分裂属性。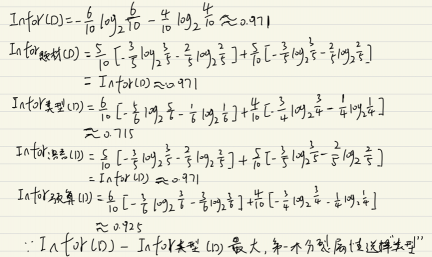
第一个属性选择”类型”作为分裂属性,决策树如下: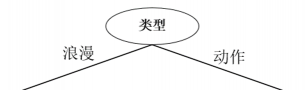
然后对于‘类型‘节点的左子树,当类型 == ‘浪漫’时,数据如下: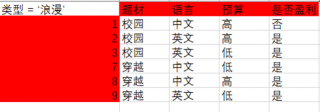
再次计算信息增益
选择题材作为分裂属性,决策树如下: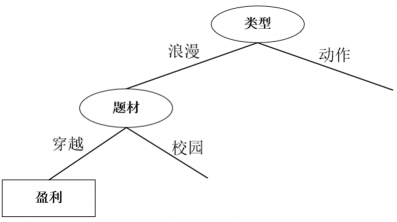
对于‘题材‘节点的右子树,当类型 == ‘浪漫’ and 题材 == ‘校园’时,表格如下:
再次计算信息增益
选择语言做为分裂属性,其决策树如下: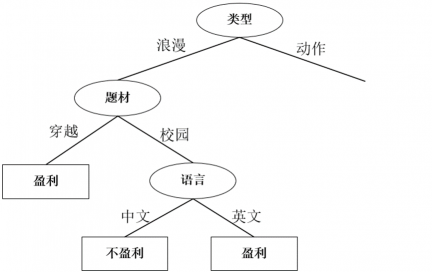
然后对于‘类型‘节点的右子树,当类型 == ‘动作’时,图表变成如下:
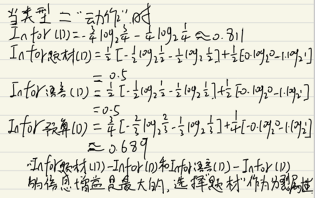
由于选择题材和语言的信息增益相等,并且同时为最大,所以选择任意一个做为分裂属性都可以,我选择题材做为分裂属性。其决策树如下: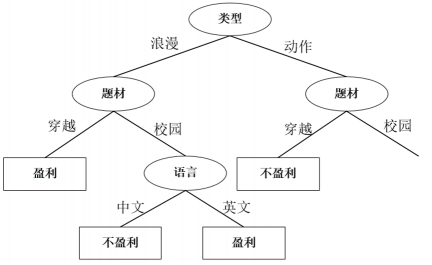
对于‘题材’节点的右子树,当类型 =‘动作’ and 题材= ‘校园’时,表格如下:

选择语言做为分裂属性,其决策树如下: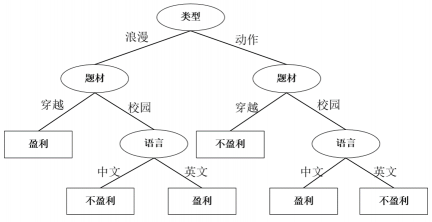



评论(0)
您还未登录,请登录后发表或查看评论