

一、数据类型
1.属性的定义
每一条数据可以称为数据集的一个样本,而每一条数据要用不同的特征描述出来,特征也称为属性。
属性通常分为两大类。
一类是定性描述的属性,其可以划分为标称属性,布尔属性,序值属性,不具备数的大部分性质。
一类是定量描述的属性,即数值属性,用数表示,并且具有数的大部分性质,可以是整数值和离散值。
标称属性:符号或事物的名称。但是有时候,机器学习任务中,模型只能接受数值型属性,所以可以用one-hot编码将标称属性重新编码。
二元属性:只有0和1两个状态,如果一个二元属性的两种状态有相同的权重,就说这个二元属性是对称的,如果两种状态不同,则这个二元属性是非对称的。
序值属性:提高足够的信息确定数据对象之间的序。
以上三种属性都是对对象的定性描述,描述的是对象的特征,而不给出实际的大小或数量。
数值属性:可度量的,用整数或实数表示,定量的分析对象。
区间标度属性:用相等的单位尺度度量,这种属性允许我们定量和评估值之间的差
比率标度属性:具有固定零点的属性,可以说一个值是另一个值的几倍,也可以说两个值相差多少。
离散属性:具有有限或无限个数的值,可以用整数表示,可以用也可以不用整数表示。
连续属性:连续属性和数值属性通常等价。
二、数据的统计描述方法
在对数据进行分析之前,把握数据的全貌是至关重要的,基本的统计描述方法不仅仅用来识别整个数据集的性质和特点,发现数据集中的噪声和离群点,还能够对缺失的数据值进行补全。
1.数据的中心趋势度量
中心趋势指一组数据向某一中心值靠拢的倾向。
算术均值:X=(X1+X2+…+Xn)/n
如果有权重,可以计算加权算术均值。
加权算术均值:X=(X1f1+X2f2+…+XnXn)/(f1+f2+…+fn)
均值对极端值极为敏感,为了抵消极端值的影响,可以使用截断均值。
对于倾斜的数据,均值不能很好的反应数据的中心,可以使用中位数或众数。
中位数:一组数据按从小到大(或从大到小)的顺序依次排列,处在中间位置的一个数(或最中间两个数据的平均数)。
众数:是集合中出现频率最高的值。
中列数:是数据集的最大和最小值的平均值。
近似中位数:当数据集很大时,计算中位数开销很大,可以计算近似中位数来反映中心趋势。
公式如下: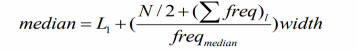
其中,L1是中位数区间的下界,N是整个数据集中数据的个数,(∑freq)l是低于中位数区间的所有区间的频率和,freqmedian是中位数区间的频率,而width是中位数区间的宽度。
偏斜度是对数据分布偏斜方向以及程度的度量。
在偏态分布中,当偏斜度为正值,称为分布正偏,众数位于平均值的左侧
当偏斜度为负值,称为分布负偏,众数位于平均值的右侧
在完全对称的数据中,均值,中位数,众数都是同一个值。
可以根据众数,中位数,算术平均值之间的关系来判断分布是左偏态还是右偏态。
2.数据的离散趋势度量
离散趋势度量反应了数据集中的值远离其中心值得程度。离散趋势度量主要有极差,分位数,五数概括,方差和标准差。
极差:又称为全距,是指数据集中最大值和最小值之差。极差只考虑最大值和最小值,所以只反映了最大得离散程度情况。
四分位数:将一组数据集从小到大排列,然后将数据划分为4等份,一共可以取出3个数据划分点。这三个数据划分点就是四分位数。分别为Q1,Q2,Q3。
四分位距:IQR = Q3 - Q1
五数概括:数据集分布形状得完整概括包括中位数,四分位数Q1和Q3,最大,最小观测值。
盒图:五数概括得可视化,其中最小观测值min = Q1 - 1.5IQR
最大观测值max = Q3 + 1.5IQR。
离群点是大于最大观测值或者小于最小观测值的点。
方差和标准差: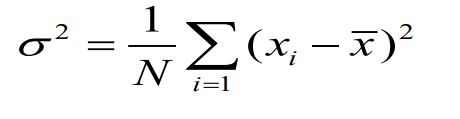
方差低表示越趋向于平均值,越稳定。
标准差是方差的平方根。
三、数据对象关系的计算方法
数据对象关系的计算方法围绕一组对象的多个属性数据展开。
主要分为两种:对象之间的相似性,属性之间的相关性(要区分对象之间和属性之间)
1.度量数据对象的相似性
假设有n个对象,每个对象有n个属性,则构建的矩阵如下:
其中n行代表n个元组,即数据对象。n列代表每一个数据对象有n个属性。
d(i,j)来表示两个数据对象i和j之间的距离值,也就是相似度值,d(i,j)越大,表明两者距离越大,相似性越小。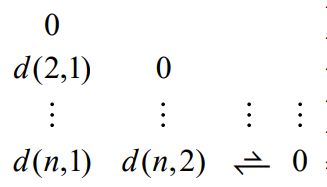
根据不同的属性来定义不同的距离函数d(i,j)
标称属性:两个对象i和j之间的距离可以根据对象属性的匹配率来计算。
公式如下:
其中p是所有属性的数目,m是两个对象取值相同的属性数目。
二元属性:分为对称的和非对称的两种情况。
在分析对象间相似性时,对称的二元属性两个状态取值的权重是一样的,而非对称的二元属性两个状态取值的权重是不一样的。

其中a是i和j同时取1的属性数,b是i取1,j取0的属性数。c是i取0,j取1的属性数,d是i取0j取0的属性数。
如果二元属性是对称的,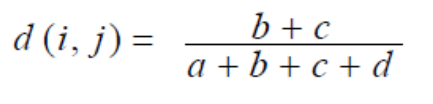
如果二元属性是非对称的(而且当属性值为1时权重最高),则可以在属性总数中减去同时为0的情况。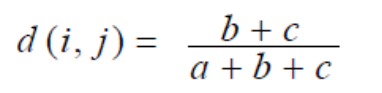
数值型属性:首先要做规范化处理,做到无量纲差别,然后再选用距离度量公式。
常见的有欧氏距离,曼哈顿距离,切比雪夫距离,闵可夫斯基距离,标准化欧氏距离。
欧氏距离:
曼哈顿距离: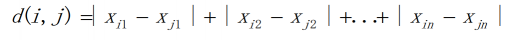
切比雪夫距离:
闵可夫斯基距离:是欧氏距离和曼哈顿距离的推广。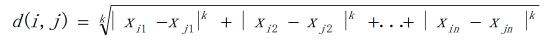
标准化欧氏距离:
其中的s1,s2,…,sn是不同属性的标准差。
标准化欧式距离也可以看成加权的欧氏距离。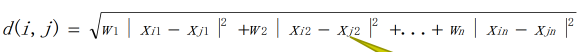
序值属性:序值属性的值具有有意义的序或排位。
主要思想是将序值属性映射到[0,1]之间的连续型数值属性,然后再根据数值型属性的距离度量公式来计算。
(1)第i个对象的f值为xi,f,属性f有Mf个有序状态,用对应的秩(排位)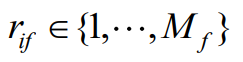
来代替xi,f
(2)将每个属性的值映射到[0,1]上,映射公式如下: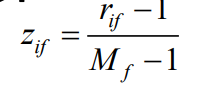
(3)使用数值属性的距离度量公式来计算。
比例标度型属性:
两种方法:
(1)采用与处理区间标度同样的方法
(2)对比例标度变量进行对数变换
Jaccard相似性:通过计算两个对象集合的交集相对大小来衡量相似性。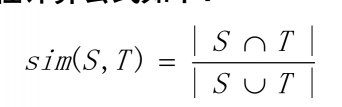
余弦相似性:取值范围为[-1,1],其值越大,两个向量夹角越小,两个样本的相似性也就越大。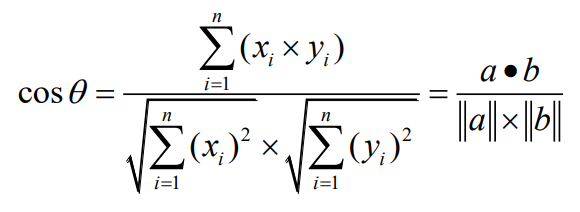
2.度量数据对象的相关性
皮尔逊相关系数:线性相关系数,取值范围[-1,1],绝对值越大,表明相关度越高。如果相关系数为0,表明两个变量间不是线性相关,但有可能是其他方式相关。一般用于处理数值属性间的相关性。
公式如下: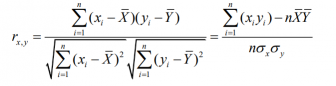
其中,n为样本个数,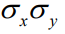 为他们的标准差。
为他们的标准差。
斯皮尔曼相关性系数:与皮尔满相关性系数不同的地方是:建立在秩次的基础上,适应范围更广。
协方差:
协方差通常用于衡量两个变量的总体误差。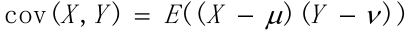
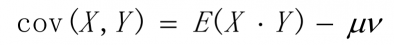
其中,u = E(x),v = E(y)
卡方检验:对于标称属性,通常使用卡方检验。卡方检验的思想在于比较理论频数和实际频数的吻合程度。



评论(0)
您还未登录,请登录后发表或查看评论