

深入解析DI-engine训练文件夹:串行与并行模式详解
DI-engine通过创建不同的文件夹和文件来管理训练过程中的数据和模型状态。这些文件夹对于理解模型是如何训练的以及如何进行性能监控至关重要。但对于初学者来说,这些文件夹可能看起来实在是一团麻又难以理解。在本篇博客中,我们将详细解释串行与并行训练模式下DI-engine生成的文件夹,快速了解它们的功能和用途。
串行模式下的文件夹结构
在串行模式下,DI-engine会创建一个基本的文件树,用来存储日志(logs),模型检查点(checkpoints),配置信息等。下面是一个典型的文件夹结构示例:
cartpole_dqn
├── ckpt (模型检查点)
│ ├── ckpt_best.pth.tar (最佳模型)
│ ├── iteration_0.pth.tar (迭代0的模型)
│ └── iteration_561.pth.tar (迭代561的模型)
├── log (日志文件夹)
│ ├── buffer (数据缓冲区日志)
│ ├── collector (数据采集器日志)
│ ├── evaluator (评估器日志)
│ ├── learner (学习器日志)
│ └── serial (串行模式下的tensorboard日志)
└── total_config.py (完整配置文件)
例如: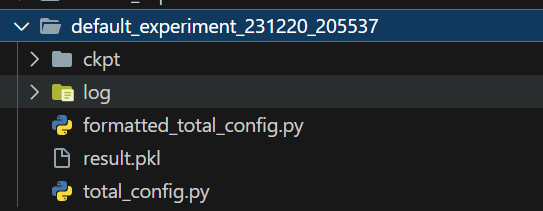
ckpt文件夹
在ckpt文件夹中,您会发现模型训练过程中保存的检查点文件,包括最佳模型ckpt_best.pth.tar和其他迭代的模型文件。这些文件可以使用PyTorch的torch.load函数加载。
log文件夹
log文件夹包含了几个子文件夹,每个子文件夹记录了训练过程中不同组件的日志信息。
- buffer: 记录数据缓冲区(buffer)的日志,如数据使用情况、采样信息等。
- collector: 记录数据采集过程的日志,如每秒采集的样本数等。
- evaluator: 记录评估器与环境交互的详细日志,包括奖励信息和每个episode的平均步数。
- learner: 记录学习器(learner)的日志,包括学习率、损失等信息。
所有的tensorboard日志文件在serial文件夹中集中保存,以便在TensorBoard中进行可视化分析。
log/buffer
buffer文件夹下的buffer_logger.txt文件提供了数据缓冲区(buffer)的关键信息。数据缓冲区是强化学习中用于存储经验样本的地方,通常以回放缓冲区(replay buffer)的形式存在。
采样信息
buffer_logger.txt中会记录缓冲区的使用情况。这包括了以下指标:
use_avg:平均使用率,表示缓冲区的使用程度。use_max:最大使用率,显示缓冲区用量的峰值。priority_avg:平均优先级,用于优先经验回放。priority_max:最大优先级,记录所存数据的最大优先级值。priority_min:最小优先级,记录所存数据的最小优先级值。staleness_avg:平均陈旧度,表示数据在缓冲区中的平均存放时间。staleness_max:最大陈旧度,表示所有数据中存放时间最长的数据。
通过监控这些指标,我们可以对数据的质量和使用情况有一个直观的了解。
吞吐量信息
此外,还会记录与吞吐量相关的信息,例如:
pushed_in:新加入缓冲区的数据数量。sampled_out:从缓冲区取出用于学习的数据数量。removed:从缓冲区中删除的数据数量。current_have:当前缓冲区中有效数据的数量。
这些信息对于了解缓冲区的动态很有帮助,可以帮助我们判断是否需要调整数据采样或存储策略。
log/collector
collector文件夹包含了collector_logger.txt日志文件,记录了与环境交互相关的信息。这些信息对于了解数据采集过程至关重要,它包括了:
在收集器文件夹中,有一个名为“collector_logger.txt”的文件,其中包含一些与环境交互相关的信息。
设默认置 n_sample 模式。 collector 的基本信息: n_sample 和 env_num. n_sample 表示采集的数据样本数. 对于 env_num,它表示collector将与多少个环境交互。
例如:
- episode_count: 收集数据的episode数量
- envstep_count: 收集数据的envstep数量
- train_sample_count: 训练样本数据个数
- avg_envstep_per_episode: 每个 eposide中平均的 envstep
- avg_sample_per_episode: 每个episode中的平均样本数
- avg_envstep_per_sec: 每秒平均的env_step
- avg_train_sample_per_sec: 每秒平均的训练样本数
- avg_episode_per_sec: 每秒平均episode数
- collect_time: 收集时间
- reward_mean: 平均奖励
- reward_std: 奖励的标准差
- each_reward: collector与环境交互时的每个episode的奖励。
- reward_max: 最大reward
- reward_min: 最小reward
- total_envstep_count: 总 envstep 数
- total_train_sample_count: 总训练样本数
- total_episode_count: 总 episode 数
- total_duration: 总持续时间
log/evaluator
在evaluator文件夹中的evaluator_logger.txt文件,则记录了评估器与环境交互时的一些关键信息,这对于理解模型的表现和做出调整至关重要。
其中包含有关 evaluator 与环境交互时的一些信息。
- [INFO]: env 完成episode,最终奖励:xxx,当前episode:xxx
- train_iter: 训练迭代数
- ckpt_name: 模型路径,如iteration_0.pth.tar
- episode_count: episode计数
- envstep_count: envstep计数
- evaluate_time: evaluator花费的时间
- avg_envstep_per_episode: 每个episode的平均envstep
- avg_envstep_per_sec: 每秒的平均envstep
- avg_time_per_episode: 每秒的平均episode
- reward_mean: 平均奖励
- reward_std: 奖励的标准差
- each_reward: evaluator与环境交互时的每个episode的奖励。
- reward_max: 最大reward
- reward_min: 最小reward
log/learner
learner文件夹中的learner_logger.txt文件,提供了关于训练过程的详细日志,包括策略神经网络的架构和性能指标,如当前的平均学习率和平均总损失。我们可以通过这些信息理解模型训练的进度和存在的问题。
TensorBoard整合
DI-engine 将串行文件夹中的所有 tensorboard 文件保存为 一个 tensorboard 文件 ,而不是各自的文件夹。 因为在跑如果跑n个实验的时候,当n很大时,4*n个各自的tensorboard文件不容易判别。 所以在串行模式下,所有的 tensorboard文件都在串行文件夹中 (但是,在并行模式下,tensorboard文件位于各自的文件夹中)。
并行模式下的文件夹结构
在并行模式下,DI-engine的文件夹结构更为复杂,因为它需要管理多个并行运行的实例。除了上述的ckpt和log文件夹,还会有额外的data和policy文件夹。
cartpole_dqn
├── ckpt (模型检查点)
├── data (数据文件)
├── log (日志文件夹)
│ ├── buffer (数据缓冲区日志)
│ ├── collector (数据采集器日志)
│ ├── commander (指挥官日志)
│ ├── evaluator (评估器日志)
│ └── learner (学习器日志)
└── policy (策略文件夹)
另附一张详细文件结构图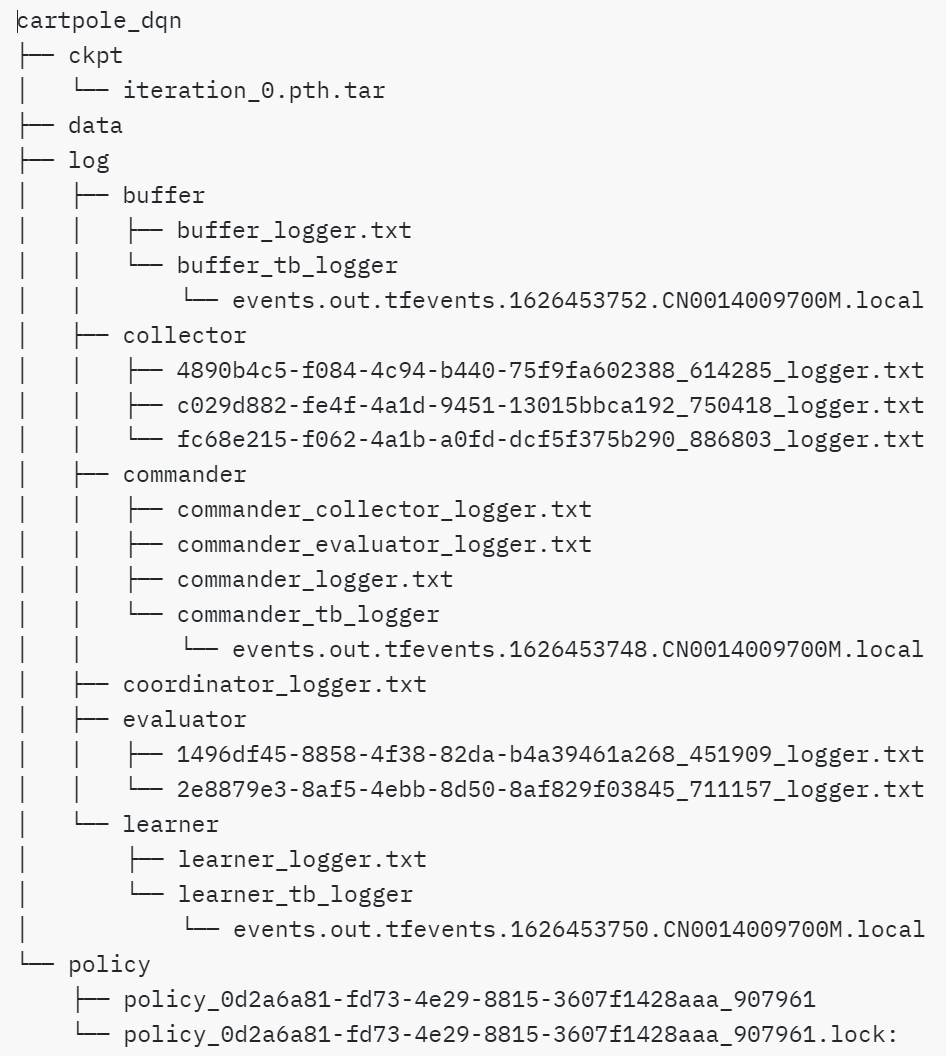
ckpt文件夹
ckpt文件夹的作用与串行模式下相同,用于存储模型的检查点。这些检查点可以是定期保存的模型状态,也包括了性能最佳的模型状态(ckpt_best.pth.tar)。这些文件使模型的训练过程可以中断和继续(所以非常重要),也允许我们在完成训练后评估最优模型。
data文件夹
在data文件夹中,存储了分布式训练过程中生成的数据文件。这些文件包含了模型训练所需的元数据和文件数据,其中元数据存储在内存中,而文件数据保存在文件系统中。
policy文件夹
policy文件夹包含策略参数,这在并行模式下尤为重要,因为不同的collector可能需要访问最新的策略来采集数据。learner更新参数后,会将这些参数写入策略文件中,然后coordinator会将这些更新的策略分发给各个collector。
log文件夹的并行结构
与串行模式不同,log文件夹在并行模式下包含了更多的子文件夹,每个子文件夹记录了不同实例的日志信息,允许我们跟踪和分析每个并行实例的性能:
- buffer: 与串行模式类似,但会有额外的tensorboard日志文件夹
buffer_tb_logger。 - collector: 包含多个
collector_logger.txt文件,每个文件记录一个collector实例的信息。 - evaluator: 与collector类似,包含多个记录不同evaluator实例信息的
evaluator_logger.txt文件。 - learner: 包含学习器的日志文件
learner_logger.txt和tensorboard日志文件夹learner_tb_logger。 - commander: 包含指挥官(commander)相关的日志文件,协调collector和evaluator的信息。
log/buffer
- buffer子文件夹下的buffer_logger.txt记录了缓冲区使用的详细情况。这包括数据的采样信息和吞吐量,帮助我们了解数据是如何被使用和更新的。buffer_tb_logger子文件夹包含TensorBoard的事件文件(events.out.tfevents),用于可视化分析。
log/collector
- collector子文件夹下可能有多个collector_logger.txt文件,每个文件记录一个数据采集器(collector)的日志。这些日志帮助我们监控和分析每个collector在环境中采集数据的效率和质量。
log/commander
- commander子文件夹包含几个日志文件和TensorBoard的事件文件夹。commander_collector_logger.txt、commander_evaluator_logger.txt、commander_logger.txt分别记录了指挥官(commander)对collector和evaluator的指令和整体协调情况。
- 在并行模式下,指挥官(commander)负责整合和协调不同collector和evaluator的行为,所以这些日志文件对于理解整个并行系统的运作至关重要。
log/evaluator
- evaluator子文件夹下的evaluator_logger.txt文件记录了评估器(evaluator)与环境交互的细节,包括每个评估周期的奖励信息和评估统计数据。
log/learner
-
learner子文件夹中的learner_logger.txt记录了学习器(learner)的学习进度,包括损失和评估结果等。learner_tb_logger子文件夹存放了TensorBoard的事件文件,用于可视化学习过程。
-
每个
tb_logger文件夹中的events.out.tfevents文件可以被tensorboard工具使用,以图形化形式展现训练过程的各种统计数据。
优势分析
初始开发与测试(串行模式)
-
快速原型设计: 使用串行模式我们可以进行快速原型设计和测试。帮助我们验证想法,调整模型架构,测试不同的超参数,如果使用并行环境就得复杂的环境设置。
-
调试与分析: 在串行模式下,通过检查log文件和TensorBoard的输出来调试模型和分析性能。由于所有日志都集中在一个地方,可以简化报错的排除流程。
-
模型验证: 使用ckpt文件夹中的模型检查点进行验证。如果某个检查点表现良好,可以考虑将其作为并行训练的起点。
大规模训练与优化(并行模式)
-
扩展性测试: 当模型在串行模式下表现稳定后,切换到并行模式用以测试模型的扩展性。
-
并行监控: 利用并行模式下的log文件夹中的多个日志文件进行详细监控。监控每个collector和evaluator的性能,以及通过commander日志来了解整体协调情况。
-
数据管理: 在并行模式下,使用data文件夹来管理大规模的数据。
-
策略同步: 利用policy文件夹来同步策略参数。可以确保所有collector都有最新的策略信息以保持数据采集的一致性和有效性。
-
分布式调优: 考虑到并行模式下的不同实例可能会有不同的性能,使用ckpt文件夹中的检查点和learner日志来调优模型,能基本保证所有实例都能够有效学习。
总结一下
串行模式适合用于模型的快速原型设计、调试和初步测试,而并行模式则适用于大规模的数据处理和模型训练。合理地利用这两种模式的优势,可以使强化学习的开发过程更加高效和系统化。
强化学习项目通常是迭代和探索性的。通过利用DI-engine提供的这些日志和文件结构,咱们可以构建一个反馈快速、适应用于大规模的训练优化。通过并行模式下的日志和文件夹,可以对整个训练过程进行更深入的监控和分析,从而精细调整策略并提高模型的性能和效率。



评论(0)
您还未登录,请登录后发表或查看评论