

一、RNN简介
循环神经网络(Recurrent Neural Network, RNN)是一类用于处理序列数据的神经网络。与传统的前馈神经网络不同,RNN引入了“内部状态”(或称为“隐藏状态”),使得网络能够存储过去的信息,并利用这些信息影响后续的输出。这个内部状态的更新过程使得RNN能够处理不同长度的输入序列,比如文字或语音数据。
RNN的特点是在不同时间步的单元之间存在连接,形成一个沿时间维度展开的有向图。这种结构允许RNN捕捉序列中随时间变化的动态特征,这使得它非常适合时序数据相关的任务,如自然语言处理、语音识别、股票预测等。
RNN在深度强化学习中的应用
在深度强化学习(Deep Reinforcement Learning, DRL)中,RNN被用于解决具有时间依赖性的决策问题。例如,DRQN(Deep Recurrent Q-Learning Network)算法结合了RNN和Q-Learning,以处理在Atari游戏等环境中可能遇到的不完全信息问题。
RNN的变体
随着研究的深入,研究者们发现传统的RNN容易出现梯度消失或梯度爆炸的问题,这限制了模型处理长序列的能力。为了解决这一问题,人们提出了RNN的一些变体,最著名的包括长短期记忆网络(Long Short-Term Memory, LSTM)和门控循环单元(Gated Recurrent Unit, GRU)。这些变体通过引入门控机制来更有效地控制信息的流动,从而更好地学习长距离依赖。
RNN在MDP中的作用
在马尔可夫决策过程(Markov Decision Process, MDP)中,智能体在每个时间步需要根据当前的观测状态以及之前的历史状态来做出决策。RNN通过其内部状态的持续更新,使得智能体能够结合历史信息来进行当前的行为选择。
DI-engine对RNN的支持
DI-engine是一套深度强化学习框架,它支持RNN网络,并提供用户友好的API,使得研究者和开发者能够更容易地实现RNN及其变体。通过这些API,用户可以将RNN集成到他们的强化学习模型中,以解决需要处理序列数据的复杂任务。
DI-engine中的相关组件

这里我们简要的分析一下ding/torch_utils/network/rnn.pyrnn.py
主要功能是实现了不同类型的LSTM单元:
-
定义了一些工具函数:
- is_sequence: 判断输入是否是列表或元组
- sequence_mask: 根据序列长度生成掩码
- LSTMForwardWrapper: 封装LSTM的前后处理逻辑
-
实现了三种LSTM单元:
- LSTM: 自定义的LSTM单元,使用了LayerNorm
- PytorchLSTM: 封装PyTorch中的nn.LSTM,格式化输入输出
- GRU: 封装了nn.GRUCell,也格式化输入输出
-
get_lstm: 根据输入参数返回不同的LSTM单元实现
- 支持’normal’,’pytorch’,’hpc’,’gru’四种类型
- hpc类型需要调用HPC平台的实现,其它为普通PyTorch实现
-
每种LSTM单元都实现了forward函数,区别在于:
- 输入输出格式化的不同
- 是否使用了LayerNorm
- 对于隐状态,可以返回Tensor或List两种格式
-
forward函数中会调用LSTMForwardWrapper的钩子函数进行输入输出封装处理
这样设计使得不同的LSTM实现可以通过统一的接口进行调用,隔离了输入输出格式的处理逻辑。该程序实现了灵活可配置的LSTM单元,通过组合PyTorch基础模块,提供了清晰和统一的接口。
LSTM类中forward函数的实现的非常优雅:
- 调用钩子函数进行输入状态的预处理,提高复用性
- 逐层、逐时间步执行LSTM计算流程,代码结构清晰
- 使用列表保存每一时间步的输出,最后stack起来
- 添加可配置的dropout操作
- 封装next_state的输出格式,提高灵活性
这样的实现既考虑了计算流程的清晰性,也提高了接口的灵活性,使得LSTM单元更易于复用和扩展。
def forward(self,
inputs: torch.Tensor,
prev_state: torch.Tensor,
list_next_state: bool = True) -> Tuple[torch.Tensor, Union[torch.Tensor, list]]:
# 调用钩子函数进行输入状态的预处理
prev_state = self._before_forward(inputs, prev_state)
H, C = prev_state
x = inputs
next_state = []
for l in range(self.num_layers):
h, c = H[l], C[l]
new_x = []
for s in range(seq_len):
# 计算不同门的值
gate = ...
i, f, o, u = gate
# LSTM计算公式
c = f * c + i * u
h = o * torch.tanh(c)
new_x.append(h)
next_state.append((h, c))
x = torch.stack(new_x, dim=0)
# 添加dropout
if self.use_dropout and l != self.num_layers - 1:
x = self.dropout(x)
# 封装next_state的格式
next_state = self._after_forward(next_state, list_next_state)
return x, next_state
DI-engine 中哪些策略支持RNN结构
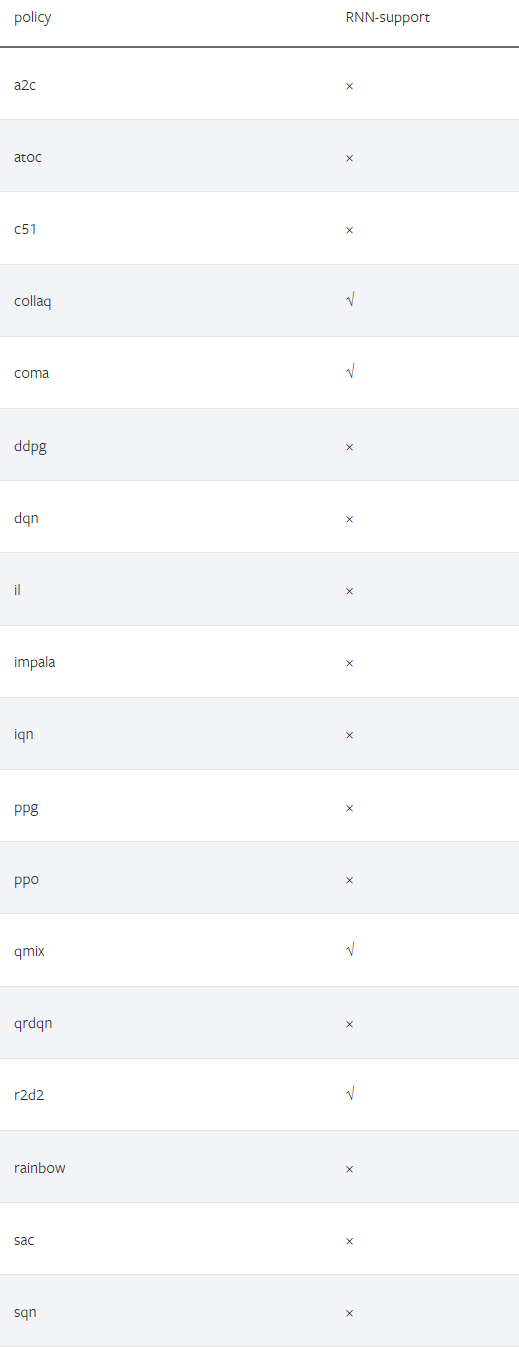
二、在 DI-engine 中使用 RNN
构建包含 RNN 的模型
我们可以使用 DI-engine 的已实现的包含 RNN 的模型或我们自己定义的模型。
使用 DI-engine 已实现的模型:
DI-engine 的 DRQN 对于离散动作空间环境提供 RNN 支持(默认为 LSTM)。我们可以在配置中指定模型类型也可以在策略中设置默认模型以使用它。
# in config file
policy=dict(
...
model=dict(
type='drqn',
import_names=['ding.model.template.q_learning']
),
...
),
...
- policy 是一个字典,其中包含了配置智能体行为的参数。
- model 是 policy 字典中的一个键,它的值也是一个字典,用于定义模型的具体设置。
- 在 model 字典中,type 键设置为 ‘drqn’,表明我们使用的模型类型是 DRQN。
- import_names 是一个列表,包含了 DRQN 模型实现的模块路径,ding.model.template.q_learning 是模型实现代码所在的位置
# or set policy default model
def default_model(self) -> Tuple[str, List[str]]:
return 'drqn', ['ding.model.template.q_learning']
在上述方法中:
-
方法 default_model 返回一个元组,第一个元素是模型的名称 ‘drqn’,第二个元素是包含模型实现模块路径的列表 [‘ding.model.template.q_learning’]。
使用定制模型。 请参考 https://www.guyuehome.com/45791. 我们自定义的模型的输出 dict 应包含 next_state 键。class your_model(nn.Module): def forward(x): # the input data `x` must be a dict, contains the key 'prev_state', the hidden state of last timestep ... return { 'logit': logit, 'next_state': hidden_state, ... }使用模型 Wrapper 将模型包装在策略中
RNN 的模型需要在连续决策中保持一定的状态信息。RNN 类型的模型依赖于隐藏状态来保持和传递时间序列信息
DI-engine 提供的 HiddenStateWrapper 可以管理和维护 RNN 模型在序列决策中的隐藏状态。这个包裹器允许用户将其模型嵌入到策略中。我们只需要在 策略的学习/收集/评估的初始化阶段来包装模型。 HiddenStateWrapper 会帮助智能体在模型计算时保留隐藏状态(hidden states),并在下一次模型计算时发送这些隐藏状态(hidden states)。
HiddenStateWrapper工作流程可以表示为下图: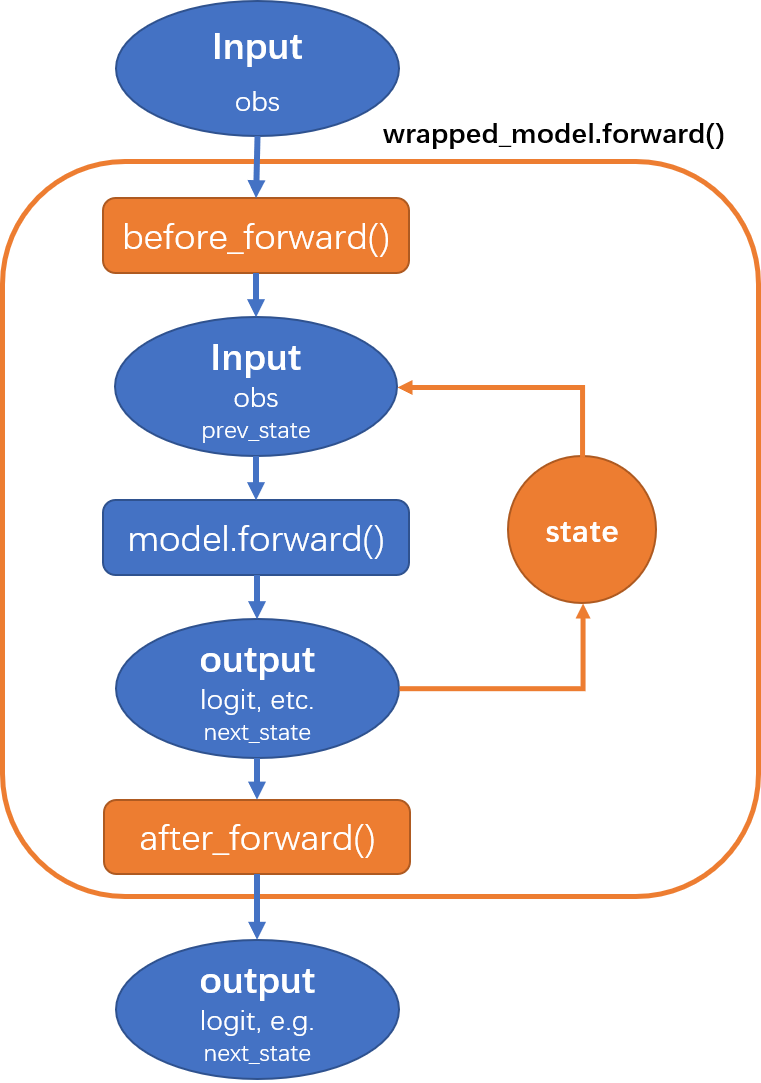
# In policy class your_policy(Policy): def _init_learn(self) -> None: ... self._learn_model = model_wrap(self._model, wrapper_name='hidden_state', state_num=self._cfg.learn.batch_size) def _init_collect(self) -> None: ... self._collect_model = model_wrap( self._model, wrapper_name='hidden_state', state_num=self._cfg.collect.env_num, save_prev_state=True ) def _init_eval(self) -> None: ... self._eval_model = model_wrap(self._model, wrapper_name='hidden_state', state_num=self._cfg.eval.env_num)这个策略类包含三个初始化的方法,分别用于学习(
_init_learn)、数据收集(_init_collect)和评估(_init_eval)阶段。这三个方法中用到了model_wrap函数来包装策略中的模型,以便在这些不同阶段管理模型的隐藏状态。
现在,我们逐个分析这三个方法:
_init_learn 方法
def _init_learn(self) -> None:
...
self._learn_model = model_wrap(
self._model, wrapper_name='hidden_state', state_num=self._cfg.learn.batch_size
)
在学习(训练)阶段初始化时,_init_learn 方法使用 model_wrap 函数包装了 self._model(策略的模型)。这里,wrapper_name='hidden_state' 指定了使用隐藏状态包装器,state_num=self._cfg.learn.batch_size 指定了隐藏状态的数量,它应该与训练批次大小相同。这是因为在学习过程中,每个批次的数据都可能需要独立的隐藏状态。
想象一下,你在学习新东西时,每次都会记下你学的内容,这样下次就能接着学。这里的 _init_learn 方法就是在做这个事。它用 model_wrap 来设置模型,让它能记住每次学习的状态。state_num 是记忆的数量,得跟我们学习的数据批次大小一样,理由很简单,每批数据都可能得单独记点东西。
_init_collect 方法
def _init_collect(self) -> None:
...
self._collect_model = model_wrap(
self._model, wrapper_name='hidden_state', state_num=self._cfg.collect.env_num, save_prev_state=True
)
数据收集阶段的初始化在 _init_collect 方法中进行。同样使用 model_wrap 函数包装模型,这次的 state_num 设置为 self._cfg.collect.env_num,这代表了环境的数量,因为在并行数据收集时,每个环境需要维护自己的隐藏状态。save_prev_state=True 参数指示包装器在每个时间步之后保存前一个状态,这对于维护连续决策中的状态连贯性至关重要。
说人话就是,当你在不同的环境里搜集信息时,每个环境的情况都可能不一样,你得分别记下每个环境的信息。_init_collect 方法就是按这个逻辑来的。state_num 这次是环境的数量,因为我们可能会同时在好几个地方收集数据。save_prev_state=True 告诉模型,别忘了每次收集完后记下来,这样下次就能知道上次发生了啥。
_init_eval 方法
def _init_eval(self) -> None:
...
self._eval_model = model_wrap(
self._model, wrapper_name='hidden_state', state_num=self._cfg.eval.env_num
)
评估阶段的初始化在 _init_eval 方法中执行。这里也使用了 model_wrap 来包装模型,state_num 设置为 self._cfg.eval.env_num,指的是评估过程中使用的环境数量。在评估时,每个环境同样需要有自己的隐藏状态,确保评估的准确性。
评估就像是考试,你得记住你在哪个教室考的试,每个教室的情况可能都不同。_init_eval 方法就是这么设定的,用 model_wrap 来管理每个环境的状态。这里的 state_num 是评估时用的环境数量。
把这些放一块儿看,这段代码就是通过 model_wrap 和一个叫 hidden_state 的隐藏状态包装器,在学习、收集数据和评估这三个阶段,让模型的记忆得以保存,并在需要的时候可以用。这样做的好处是,用 RNN 这种需要记忆的网络来做决策就容易多了,特别是在需要连续记忆的任务上。
现在我们完成了RNN模型的构建以及将模型包裹在策略中,下一篇我们将完成:原始数据处理、初始化隐藏状态以及Burn-in(Optional)



评论(0)
您还未登录,请登录后发表或查看评论