

———— 满堂花醉三千客,一剑霜寒十四州。
在前面的篇章中,我们更多考虑的是假设数据集⾥的数据独⽴同分布的情形,根据这个假设,似然函数可以表示为所有数据点的概率分布的乘积。然⽽,在实际应用中,独⽴同分布的假设可能不成⽴,典型的就是顺序数据,这些数据通常是时间序列变量,比如语音信号就是在连续时间框架下的声学特征,本文将从语⾳识别任务切入,引出隐马尔科夫模型 (Hidden Markov model)。
语音识别 (Speech Recognition)
语音识别任务,可以看作是将一段语音信号先处理成声学特征向量 ,其中
表示一帧 (Frame) 特征向量,然后再将声学特征向量表示为可能的文本序列
,其中
表示一个词元 (token),可以看出声学特征向量序列的长度与文本序列长度并不一致,这就涉及到一个对齐的问题,而且将
称作可能的文本序列,是因为一段语音会有很多不同文本组合的识别结果,所以我们就要考虑识别概率最大的那个序列
,这也是语音识别的基本出发点。根绝贝叶斯公式,有
其中 被称为声学模型,
被称为语言模型。语言模型
是一系列词元序列的联合概率分布
,同理声学模型也可以表示为
。语音识别基本上可以分为两个问题,第一是如何训练出有效的声学模型和语言模型,建立一个完整的语音识别系统;由于发音等问题,系统往往会识别出多个可能的序列,第二个问题就是是如何选择出最有可能的那个结果。一个语音识别系统会定义一个词表 (vocabulary),包含有限个词汇。语音信号通过模数转换 (Analog to Digital Conversion, ADC),表示为数字化的向量形式,而这些向量包含了最原始的发音基本单位的特征,类似于英语音标和汉语拼音,然后再把这些音标或拼音元素组成词元 (token),这里的词元是一个语言的基本单位,如英文单词和汉字,对于不在词表中的词,我们全部使用一个额外的词元表示。很显然所有语言都有很多同音字词,也就意味着识别结果并不唯一,而声学模型只负责把声音转换成文字,直接识别结果可能千奇百怪完全不符合人类语言习惯,引入语言模型就很有必要,语言模型通过对识别结果进行概率评分选出最有可能的句子序列,这就是一个基本的语音识别过程。从数学的角度讲,就是找出一个合适的模型表示出公式 (1),即
。这里就需要用到隐马尔科夫模型 (Hidden Markov Model, HMM)。
前文提过马尔科夫链模型 (Markov Chain Model),使⽤概率乘积规则表示一段观测序列 的联合概率分布,即
我们假设了公式 (2) 中任意 的取值只与最近⼀次的观测
有关,⽽独⽴于其他所有之前的观测,那么就得到了⼀阶马尔科夫链 (first-order Markov chain),观测序列的联合概率分布为
元语言模型 (n-gram language model) 就是一个
阶马尔科夫链,符合这个假设的随机过程被称为马尔科夫过程。我们用
元语言模型很容易统计出训练文本中在已知 n-1 个词依次出现时第 n 个词出现的频率,将这个频率当做概率,
元语言模型就转换为概率模型,继而可用于对结果进行概率评估,即打分(score),然后排序选择出最有可能的识别结果。一般情况下使用四元语言模型即可,因为
元语言模型的存储空间是随着
呈指数增长的。通过
元语言模型的概率统计,我们可将那些概率极低的识别结果先排除掉,这样就能极大简化后续的处理,这会在后续篇幅中详细讲述。此外我们可以在后续引入一个更强大的神经语言模型,比如 LSTM 或 Transformer 语言模型进行重打分 (rescore) 获得更可靠的识别结果。
然而我们还需要一个更合适的模型来对公式 (1) 中的声学模型建模,这就需要用到隐马尔科夫模型 (Hidden Markov Model, HMM)。
隐马尔科夫模型 (Hidden Markov Model)
隐马尔科夫模型是马尔科夫模型的一个扩展,是最常见的计算 的统计模型。声学模型包含两种不同且长度不一的信号,我们求解条件概率
,其中声学信号
是已知可观测到的特征向量,因此我们称
为 HMM 的观测值 (observation),然后再将文本序列变作与观测序列等长的潜在特定状态序列 (specified state sequence)
;最后定义一个与文本序列等长的包含
个隐藏状态 (hidden state) 的序列,隐藏状态数与观测值数目彼此不受约束,这就解决了声学和文本序列的起始对齐问题。我们无法观测到任意的隐藏状态
,因此无法通过状态序列
推测条件概率,隐马尔科夫模型把这个从隐藏状态转移到观测值的概率称作转移概率 (transition propability)。这里也需要引入一些假设:
- 首先假设从一个隐藏状态转移到另一个状态只和当前时刻的状态有关,这就是马尔科夫假设 (Markov assumption)。其中转移概率是恒定的,并且与观测值和前一时刻的隐藏状态不相关;
- 其次还应假设观测值是相互独立的,这样当前观测就不会受前面的观测值影响,这被称为状态条件独立性假设 (state conditional independence assumption)。前两条假设只是为了简化模型,与实际语音信号属性相去甚远,因为一段正常语音是高度连续的,某一帧的发音很容易受前后字词转换所影响;
- 最后,我们对连续的声学信号做了离散化处理,由观测值,即声学特征向量表示,这里的离散化采样是以帧为单位提取,每一帧内的声学信号看做是静止 (stationary) 的,通常每一帧都会采样 25 ms 的数据,所以有很多声音信息未能很好的提取。
尽管有诸多限制,时至今日,HMM 仍是处理声学模型的最优方法。HMM 是一个有限状态机 (finite state machine),可作如下描述:一个 HMM 包含 N 个隐藏状态,其中有 N-2 个发射状态 (emitting states),一个起始状态 (entry state) 和一个结束状态 (exit state),还应注意执行完这个有限状态机的总时间步长为观测序列长度 ;在时间步
,从当前隐藏状态
及其对应的特定状态
转移到下一状态
和
的概率为
,同时也会有
的概率继续停留在当前状态;而观测值
也就以发射概率
随之产生。一个隐马尔科夫模型,
,就可以表示为参数集合
。这里的 HMM 是一个生成模型,用来产生观测值,也就是语音信号
的最大似然概率。由于语音信号都是时序信号,所以 HMM 是一个从左至右 (left-to-right) 的单向结构,下图给出了一个 HMM 的实例。
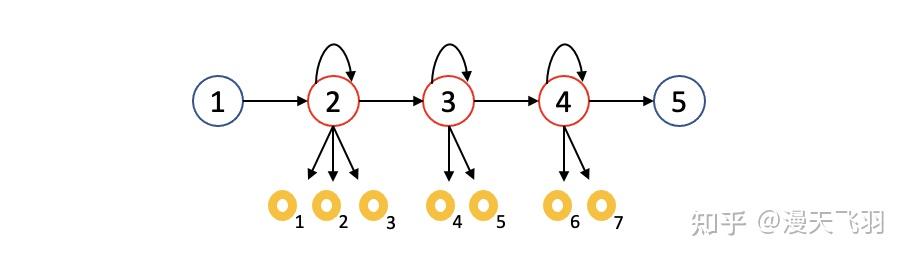
上图是一个 HMM 图例,大圈状态 1 和 5 分别是起始状态和结束状态,状态 2,3,4 是发射状态,表示隐藏状态,这里加入起始和结束状态是为了标示一次完整的 HMM 过程。声学模型研究的是给定某个文本信号 产生语音
的概率,而输入是语音信号,正好作为 HMM 中的观测数据 (observed data),对应上图中的黄色圆圈 1-7,整个 HMM 观测值和隐藏状态的联合概率为
其中 和
分别代表起始状态 1 和结束状态 5。上述图例中的 HMM 的联合概率可表示为
与直观的认知不同,声学模型的 HMM 输入是被隐藏状态产生的观测值,参数是转移概率和发射概率,输出才是隐藏状态,这是因为我们一开始就使用了贝叶斯公式的缘故,可以理解为,我们在获得一段语音数据作为观测值后,反推出究竟是什么样的一段文本才能匹配这段语音,所以 HMM 的观测值才是重点关注的对象。
HMM 的输出分布应尽可能接近从一个隐藏状态产生对应观测值的真实分布 (actual distribution of the data associated with a state),并且尽可能在数学上可计算 (be mathematically and computationally tractable),另外每一步发射概率 通常用概率密度表示,一般选择高斯分布,即
这就增加了 HMM 的参数数量。一般为方便计算我们会假设协方差矩阵为对角矩阵,即使在 HMM 中已假设观测之间相互独立,但还是得说明这是有违实际情况的:且不论语音能量谱并非严格的高斯信号,一段语音中的声学特征向量也是高度相关的 (highly correlated),甚至需要一个密集协方差矩阵 (a full covariance matrix),这就需要在提取语音信号特征时不能使用短期能量谱 (short-term power spectrum),而使用 MFCC 特征,可以一定程度上避免这个问题。但这并不代表语音识别的 HMM 就是处理这样的独立特征的,实际上语音识别 HMM 还是一个针对连续密集 (continuous density) 的语音信号设计的,不过在某些情况如使用向量量化 (vector quantisation) 时还会使用另一种针对符号数据 (symbolic data) 的离散密集 (discrete density) 型 HMM,在此先按下不表。
另外需要注意的是,语音识别中的 HMM 大致可根据输入基本单位 (basic unit) 分为两种,一种是以音素为单位固定帧切分语音信号的次词 (sub-word level) 模型,也就是每个隐藏状态产生的观测值数量相等,这里把每一帧数据代表一个音素 (phone),音素表的数量远远小于词汇表的单词数,例如英语中通常只有 40 至 60 个音素,但最好的英语语音识别系统词汇却包含 20,000 至 64,000 个单词,同样地,汉语拼音的数量也远远小于汉字数。给定一个音素集 ,我们自然可以为每个音素单独建立一个单状态 HMM,称作单音素系统 (monophone system),然而音素的上下文 (contextual information) 不同, 同一个音素就有了不同的变异体,所以我们需要建立上下文相关的 HMM,最常见的是三音素系统(triphone system);每个三音素又可用一个独立的三状态 HMM 表示,如下图所示
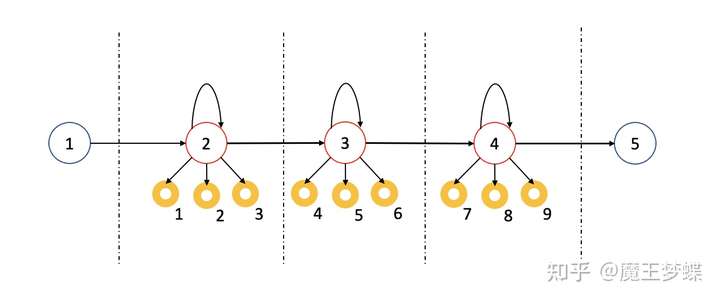
这也可以看做用三个独立的 HMM 合成的 HMM (composite HMM),所有的用于连接的起始状态和终止状态都被简化了。假设有 个音素,那么对应的三音素集就应包含
个元素。三音素集也可以分为只定义于一个单词内的上下文信息的三音素 (word internal triphone) ,和还能定义于词间上下文的三音素 (cross-word triphone),一般情况下定义于词内和词间上下文的三音素集性能更好一些。
这样,文本方面的基本单位也降解为微小的 HMM 状态。由于很多三音素并未在训练语料中出现或数量不多,我们可以将原始方法中给每一个观测值单独使用一个概率分布,改为采用状态集群 (state clustering) 的方法让声学上接近的三音素输入由相同的发射概率分布所产生,并且可以通过决策树共享三音素的状态 (phonetic decision tree clustering),所以对于共有 个音素的语言,最终保留下来的三音素状态数量远小于
,一般为几千,并把他们叫做 senones。
另外还有一种输入基本单位是独立单词的 HMM,称为孤立词训练 (isolated word training),这就需要对每个单词建立一个单独的 HMM,并且预先对语音片段按照单词进行切分,选定 HMM 的结构 (select HMM topology, i.e. the number of states and the connectivity),将训练文本中该单词的语音片段输入 HMM,使用极大似然估计 (maximum likelihood training) 训练模型参数。
相比于音素作为 HMM 基本单位,输入孤立词 (isolated word) 可以很大程度上降低搜索最佳文本序列的复杂度,这相当于我们只需要让声学模型获得对每个词的最大似然概率 (simplified to provide an estimate of likelihood for each individual word),虽然字词级别的帧数过于宽泛笼统,但只要人为的在原始语音两个单词间加入停顿,就能尽可能得到相互独立的单词 (assume words are separated from each other by detectable pauses)。于是,对于孤立词识别系统,假设我们已对包含 个单词的词汇表预训练出对应的 HMM 集合
(a set of pre-trained HMMs for each vocabulary word), 对于新输入的语音信号片段
,只需计算在每个 HMM 上的似然概率
,假设先验相等,那么似然概率最大的 HMM 对应的词就是声学模型的输出。
总结一下,HMM 用来对序列进行建模,从一个观测序列,推出对应的状态序列,也就是“由果找因”。这里的“因”一般是隐藏的,无法简单的看出来,所以叫隐藏状态。HMM 涉及的主要内容有,两组序列(隐藏状态和观测值),三种概率(初始状态概率,状态转移概率,发射概率)。我们需要解决三个基本问题:
- 在已知模型参数和一段观测序列样本的前提下,产生出这段观测序列的概率是多少;
- 同时也想知道每个观测值对应的最优隐藏状态序列;
- 最后是如何训练出模型最优参数。
先说观测序列 的产生问题,与上图所表示的 HMM 不同,实际应用中,隐藏状态是完全不可见的,好在语音识别系统中,词表数量
是提前定义好的,即每一个隐藏状态有多少种取值是已知的,所以大不了就用一种很暴力但直观的方法,对所有可能的隐藏状态序列产生出这段观测序列的概率进行加权求和。这里我们可以直接认为隐藏状态序列
与观测序列等长,因为已假设每一个隐藏状态可以取任意单词,那么闭环停留到当前状态的过程也可展开为前向过程。然而这种方法计算量会很大,如果隐藏状态有
种取值可能,观测序列长度为
,那么计算复杂度为
,为了降低复杂度,很容易想到用空间换时间的思路,只要把某一种状态序列在某一处观测值的概率记录下来,下次处于同样的位置就不用重新计算,然后使用一些递归算法就可以计算,这里有前向和后向两种计算方式。简单说一下前向计算过程 (forward algorithm), 已知参数为
的 HMM 模型,将
时刻隐藏状态为
得到观测序列
的概率记为
,设初始状态的转移概率为
,其中
,令
注意这里将参数 的下标改为与观测相同的时间步,因为语音识别的 HMM 我们已经假设某时刻的隐藏状态只与当前时刻的观测有关,而参数
括号内的
表示所有可能的隐藏状态,通过第一步,递归的初始值就得到了,然后使用递归算法 (recursive algorithms)
这里状态转移概率 是从隐藏状态
转移至
的概率,其中
,最终可得
当所有观测状态输出完毕,对所有 求和,共需计算
步,每一步进行
次乘法运算,因此计算复杂度为
。
通过上述步骤,可以依次得到每个时刻的 个状态的概率值,并最终得到已知 HMM
时产生观测序列的概率
。另一种后向算法 (backward algorithm) 和前向算法类似,顾名思义区别是后向算法从最后一个观测值出现的概率反推得到整个观测序列的出现概率;在此不做赘述。
然后接着讨论第二个基本问题,即如何找到最优状态序列 (best state sequence),这里的最优状态序列并不是指对一个未知单词的语音片段找到其对应似然概率最大的单词再组成状态文本序列,而是直接寻找似然概率最大的状态序列 (most likely state sequence),两者区别在于前者仍是基于孤立词识别系统出发,这意味着我们要事先对语音进行切片划分,但是实际上我们更多处理的是连续语音 (continuous speech)。针对这个问题,我们可以使用维特比算法。
维特比算法 (Viterbi Algorithm)
维特比算法用来解决在给定观测序列下,找到最优的隐藏状态序列。首先引入一种网格 (lattice, trellis) 的形式表示 HMM。每一个时间步 ,隐藏状态都有
种取值可能,并且任意取值都能转移到下一时刻的任意状态取值。假设一个有 4 个时间步,每个隐藏状态有 5 种取值,即一个观测序列长度为 4 词汇表大小为 5 的语音识别 HMM,可用下图直观表示
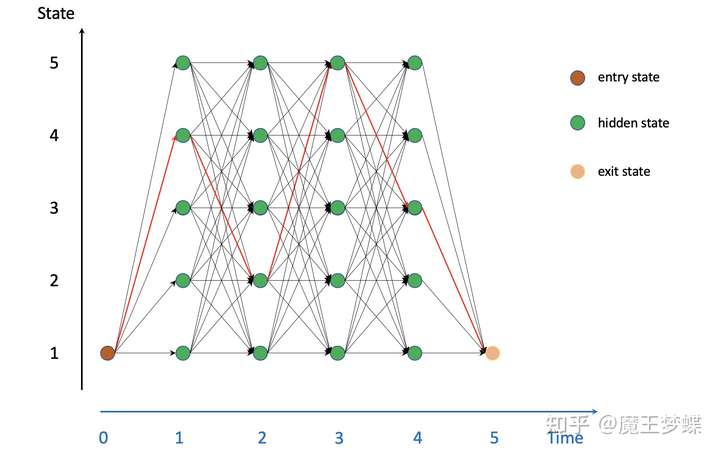
上图可以看出我们把所有可能的状态序列表示出后其网络形状确实像网格 (trellis) 或篱笆 (lattice)。似然概率最大的序列就是网格中的最优完整路径 (best complete path),可以假设是上图中的红色路。所有的状态序列或路径都可以根据路径转移概率,发射概率等乘积计算,概率最大的路径也就是最短路径,说起最短路径问题,相信大部分人都会第一时间想起动态规划 (dynamic algorithm) 算法,维特比算法就是是一种动态规划算法,解决 HMM 图中的最短路径问题,找到一种从起始到结束概率最大的隐藏状态序列。而维特比算法也是针对这种特殊有向图 (lattice) 提出的。
简单说下为什么引入维特比算法,其实上述举例可以看出,既然想找到最短路径,那么把所有路径枚举出来,然后找出最优的那条不就易如反掌吗?然而在实际应用中,对于词汇表大小 通常都数以万计,假设
,观测序列长度
,那么可能的路径共有
,这是无法计算的。同样地,我们又回到空间换时间的思路,只是前向算法时为了得到状态序列的期望概率,这里考虑的是最短路径。下面讨论维特比算法如何在给定 HMM
和长度为
的观测序列
的前提下找出最优隐藏状态序列路径
。
维特比算法只考虑任意时间步的最短路径 (a simple recursion only takes into account the most likely state sequence through the model at any point),假设在时刻 进入状态
的概率为
,在动态规划算法中,整个有向图的最短路径在时刻
经过状态
,那么这条路径从起始状态到
的子路径,一定是从起始状态到
的最短路径,利用这个思想不断地做递归,就可以以较低的计算复杂度得到最短路径,设
时刻进入状态
的最短路径
其中 是到
时刻的所有子路径, 同样引入递归的思路计算整个序列的最短路径,递归公式为
由于 已经是状态序列
的最短路径,我们只需考虑从这条路径出发在
转移到所有
个状态的概率,就能得到
时刻
的最短路径。可以发现,为了得到完整路径,还需要一个
记录得到
的最优状态,这就是空间换时间的关键 (store the local decisions made at each point in the Viterbi trellis and the traceback along the most likely path at the end of utterance)。初始化
,记录
;然后调用递归公式 (12),记录每一步的
,这一步称为回溯 (traceback);最后就能得到最短路径
。
维特比算法的核心就是在进行到 时刻时,我们只记录到
时刻所有
个状态的最短路径,因此,无论最终路径是哪一条,我们所记录的
时刻的路径中总有一条是其子路径。从复杂度的角度分析,在进行第一步
时,我们计算起始状态到各个状态的距离,由于只要一步,所有这些路径就是到每个状态的最短路径,进行了
次计算;然后第二步
,我们计算从起始状态到第二步状态的最短路径,对于第二步任意状态
的最短路径,一定会经过第一步所记录的最短路径,由此只需要进行
次计算,以后每一步时刻
计算最短路径都只需要考虑
和
时刻的状态,需要
次计算,最终计算完所有
个观测值,只需要
次计算,搜索时间也就随时间步长
线性增长。
如果不断进行概率乘积,在运算时会导致数值下溢 (the direct calculation of likelihood will cause arithmetic underflow),因此实际操作时,我们会用将其转换为对数函数的形式
维特比算法是一种非常高效的算法,在语音识别中,输入都是按照从左至右的流的方式进行的,只要处理每个状态的时间不比讲话慢,不论输入多长,语音识别永远都是实时的。当然这一切还是建立在 HMM 的假设基础上,HMM 和维特比算法也就构成了语音识别的基础框架。




评论(0)
您还未登录,请登录后发表或查看评论