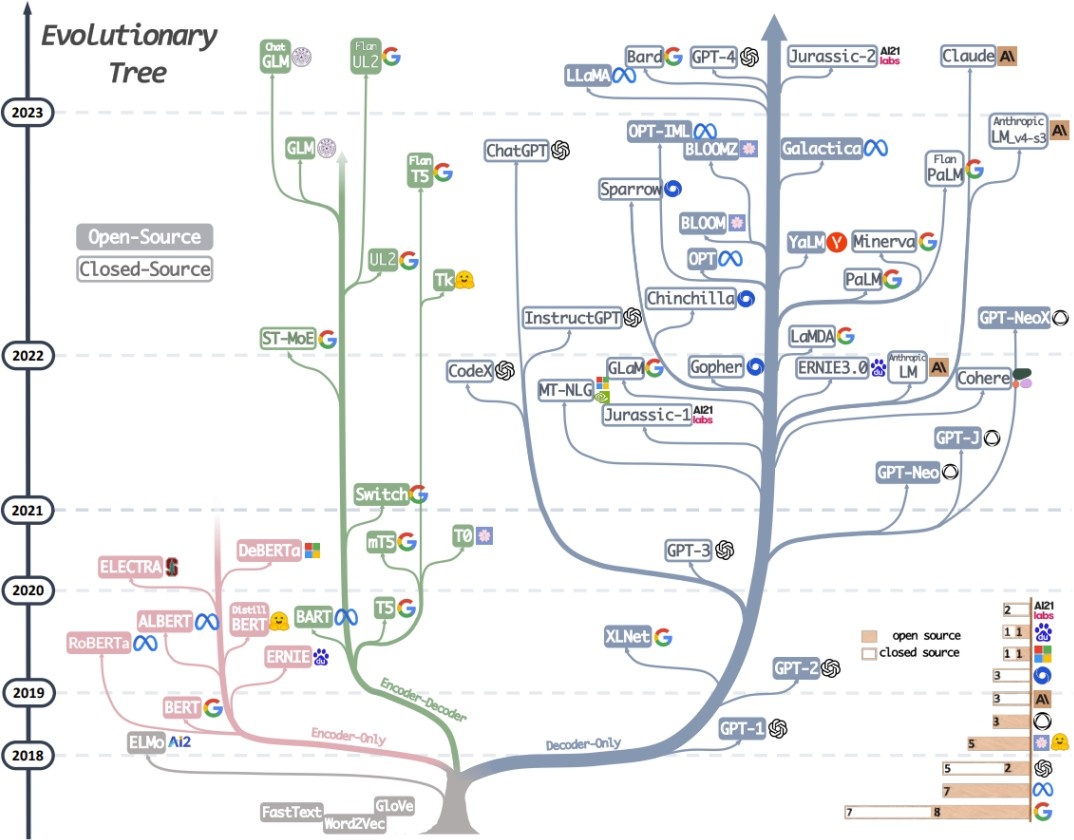
一、NLP和CV领域的一些经典算法
- nlp领域(基于LSTM和基于Transformer两种框架)
Transformer(Attention is also your need):编码器解码器自注意力机制。
论文讲解:
https://www.bilibili.com/video/BV1pu411o7BE/?spm_id_from=333.999.top_right_bar_window_history.content.click&vd_source=64703bfb8f619235a20cfe5c3c7bbb21
动画解析:
https://www.bilibili.com/video/BV1ih4y1J7rx/?spm_id_from=333.999.top_right_bar_window_history.content.click&vd_source=64703bfb8f619235a20cfe5c3c7bbb21
https://www.bilibili.com/video/BV1MY41137AK/?spm_id_from=333.788.recommend_more_video.0&vd_source=64703bfb8f619235a20cfe5c3c7bbb21
ELMo:基于RNN,对每个任务构造相对应的神经网络,基于特征(feature-based)。
Gpt:单向(左边上下文信息预测未来),基于微调(fine-tuning),解码器。
Bert:(无监督(无标签,直接挖掘数据特征关系)pre-training的方法)。大模型训练(bert来)+小模型(自己)微调,pre-training 可用于其它大模型的训练,双向(左右两侧上下文信息预测),基于transformer,利用掩码训练双向(学习token)的模型(完形填空式训练),嵌入层学习词在句子的位置(gpt为手动构造矩阵确定词位置),编码器(不适合机器翻译、文本摘要等生成式的任务)。
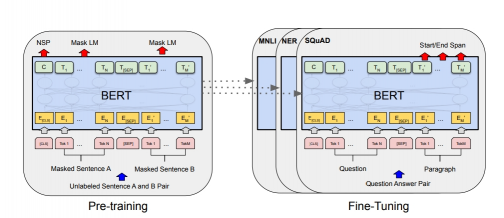
预训练(pre-training):输入句子A+B(序列)-wordpiece-切成片段-词典(词分类cls 和所有token都有关-词tok -分割sep-第二段词tok)-embedding嵌入层降维-bert层:句子层 掩码B句/随机句 | 词元层(词元、所属句子、词位置)+wordpiece生成的掩码词(80% 替换为mask标记 10%随机词 10%不变)
数据集:训练-BooksCorpus+wikipedia 测试-GLUE+Squad(Q&A数据集)
2.CV方向(目标检测、图像分类、语义分割、目标跟踪)
问题:利用transformer处理图像任务,不像nlp处理文本,二维图像展成一维面临序列长度过长的问题。
方法:CNN+transformer(LocalNetwork) / 全部采用transformer自注意力机制(stand-alone attention or Axial attention)。1.LocalNetwork把CNN卷积处理得到的特征图作为transformer的输入。2.stand-alone 孤立自注意力机制,类似CNN,自定义可接受大小的h*w的窗口作为transformer 的输入。3.Axial轴注意力机制,图像的每一横列、每一竖列分别作为transformer的输入。
问题:模型太小,不适用与大规模的图像识别任务。
Vit-Vision Transformer:图像分类,有监督(有标签/分类等辅助标签)
一副图像224*224按照16*16大小的图像块patch(元素)分为(224/16= 14)共196(14*14)个图像块(元素)(相当于transformer在nlp任务中输入的单词)-transformer的输入(序列)-全连接层 768*768(文中的D=16*16*3)-patch embedding+position embedding 图像块(patch)和位置相当于transformer的token输入((196+1图像分类)*768=151296)-(右图Encoder流程循环)layerNorm(k q v)-多头注意力学习- layerNorm-MLP(神经网络学习)
数据集:ImageNet-21K,JFT-300M

ViT-22B(2023.2最新):在原先vit模型基础上,在parallel layers(并行架构),query/key (QK) normalization(参考LayerNorm对QK(输入信息、内容)部分的计算进行一定的归一化约束,加LN层横向规范化),omitted biases(取消偏置操作)三个方面改变和调整,让整体性能在提升尺度的情况下仍可以保证训练的稳定性。
SiT: Self-supervised vIsion Transformer鉴于以自监督方式训练模型的无可置疑的优势,提出自监督视觉Transformer (SiT)。这种方法的基本假设是,通过基于整个视野的上下文从未损坏的部分恢复图像的损坏部分,网络将隐含地学习视觉完整性的概念。在这种方法中,1. 输入图像会根据可用的策略之一进行破坏:随机丢弃、随机替换、颜色失真等。2. 然后将图像分成 patch 并通过经典的 Vision Transformer 机制以及两个额外的标记,用于旋转预测的旋转标记和用于对比学习的对比标记。3. 将来自Transformer encoder的结果表示转换回补丁并重新组合以获得重建的图像。该模型应尝试减少重建图像和原始图像之间的差异。使用这种方法训练的网络的权重可以用作另一个任务的起点,例如图像分类、对象检测、分割等。
Swin-Transformer:目标分类
MAE:生成式网络
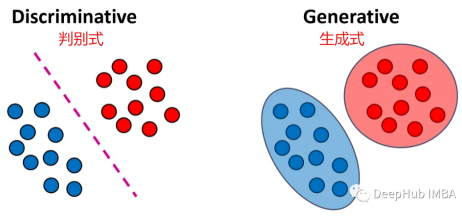
tips:生成式:学习数据分布统计,可学习输入数据与输出数据之间的多元联合分布 更适合多模态数据。判别式:学习输入数据和输出标签之间映射关系,适合处理复杂高维数据。
3、多模态任务:
图文检索(Image Text Retrieval) 视觉问答 (VQA)视觉推理 (Visual Reasoning)视觉蕴含(Visual Entailment)Swin-Transformer:目标分割
clip(及其它应用) ViLT Albef VLMo
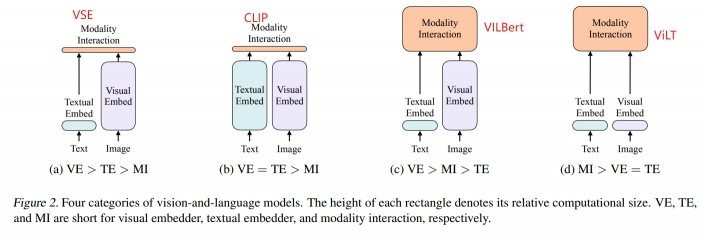
ViLT:Vision-and-Language Transformer Without Convolution or Region Supervision (无卷积和区域监督特征)、文本和图像多模态数据,VIT模型在多模态领域的应用,图像和文本分为不同的Patch-直接放入Linear Embedding层降维-token(训练耗时极大减少,准确率微减),图像增强。whole word masking文本数据增强(全单词mask 加强了文本和图像之前的联系) RandAugment图像数据增强
多模态数据融合的方法:1.single-stream 将图像和文本的序列连接起来直接放入一个模型transformer处理 2.dual-stream 用两个模型各自处理图像和文本的输入序列后在进行融合。
特征的抽取:文本-BERT 图像:1.CNN神经网络 backbone卷积网络抽取特征-RPN区域生成网络-非极大值抑制 筛选-多个特征候选框作为特征序列 2.vit 图像打成patch用transformer (liner projection线性投影降维)
通用数据集:MSCOCO ,Visual Genome ,GCC,SBU 。下游任务测试数据集:(多模态任务)VQAv2 NLVR2 (检索任务)Flickr30k MSCOCO
CLIP:Zero-Shot Learning(不提供或少量提供某些类别的训练样本,利用过去的知识,推理出新对象的具体形态,从而能对新对象进行辨认,使得计算机可以识别新事物)。流程:1.预训练 将物体的特征encoder后与物体描述的具体文本特征encoder后联系在一起训练。2.针对分类任务添加具体文本分类进行encoder。每一类的文本去和图片比较计算相似度(prompt engineering+ensembling 文本引导图像的方法,解决文本在不同语境的歧义性and图像文本描述对应and图像迁移学习的问题)。3.零样本预测,计算相似度(物体分类的文本 VS 输入图片encoder后的特征),每一类的文本去和图片比较计算相似度,输出所属的类。对比学习(文本描述与图像类似)。
自训练数据集:WIT(web image text 4亿图像文本数据集)。
其它应用:StyleClip、ClipDraw(文字引导图像生成),ViLD(物体检测、分割),文字引导视频检索。
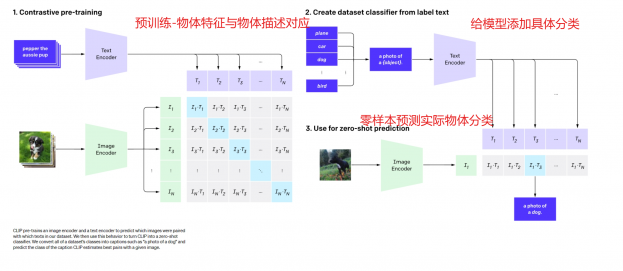
Clip的Zero-Shot transfer方法:
环境更复杂,模型泛化性更强,更适用机器人各种下游任务。流程:
import os
import clip
import torch
from torchvision.datasets import CIFAR100
# 1、读取模型
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)
# 2、下载数据集
cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False)
# 3、(1)从数据集中随机抽取一张图片,作为图片输入
# (2)取出该数据集下所有的标签,作为文字数据
image, class_id = cifar100[3637]
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device)
# 4、计算图像、文字的特征向量
# -------------------------------------------------
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
# 5、分别对图像、文字特征向量做归一化处理,
# 然后计算余弦相似度
# 取最相似的top5结果
# -------------------------------------------------
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(5)
# 6、打印结果
print("\nTop predictions:\n")
for value, index in zip(values, indices):
print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
import os import clip import torch from torchvision.datasets import CIFAR100 # 1、读取模型 device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load('ViT-B/32', device) # 2、下载数据集 cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False) # 3、(1)从数据集中随机抽取一张图片,作为图片输入 # (2)取出该数据集下所有的标签,作为文字数据 image, class_id = cifar100[3637] image_input = preprocess(image).unsqueeze(0).to(device) text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) # 4、计算图像、文字的特征向量 # ------------------------------------------------- with torch.no_grad(): image_features = model.encode_image(image_input) text_features = model.encode_text(text_inputs) # 5、分别对图像、文字特征向量做归一化处理, # 然后计算余弦相似度 # 取最相似的top5结果 # ------------------------------------------------- image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) values, indices = similarity[0].topk(5) # 6、打印结果 print("\nTop predictions:\n") for value, index in zip(values, indices): print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
import os import clip import torch from torchvision.datasets import CIFAR100 # 1、读取模型 device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load('ViT-B/32', device) # 2、下载数据集 cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False) # 3、(1)从数据集中随机抽取一张图片,作为图片输入 # (2)取出该数据集下所有的标签,作为文字数据 image, class_id = cifar100[3637] image_input = preprocess(image).unsqueeze(0).to(device) text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) # 4、计算图像、文字的特征向量 # ------------------------------------------------- with torch.no_grad(): image_features = model.encode_image(image_input) text_features = model.encode_text(text_inputs) # 5、分别对图像、文字特征向量做归一化处理, # 然后计算余弦相似度 # 取最相似的top5结果 # ------------------------------------------------- image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) values, indices = similarity[0].topk(5) # 6、打印结果 print("\nTop predictions:\n") for value, index in zip(values, indices): print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
复制
import os import clip import torch from torchvision.datasets import CIFAR100 # 1、读取模型 device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load('ViT-B/32', device) # 2、下载数据集 cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False) # 3、(1)从数据集中随机抽取一张图片,作为图片输入 # (2)取出该数据集下所有的标签,作为文字数据 image, class_id = cifar100[3637] image_input = preprocess(image).unsqueeze(0).to(device) text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) # 4、计算图像、文字的特征向量 # ------------------------------------------------- with torch.no_grad(): image_features = model.encode_image(image_input) text_features = model.encode_text(text_inputs) # 5、分别对图像、文字特征向量做归一化处理, # 然后计算余弦相似度 # 取最相似的top5结果 # ------------------------------------------------- image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) values, indices = similarity[0].topk(5) # 6、打印结果 print("\nTop predictions:\n") for value, index in zip(values, indices): print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
import os import clip import torch from torchvision.datasets import CIFAR100 # 1、读取模型 device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load('ViT-B/32', device) # 2、下载数据集 cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False) # 3、(1)从数据集中随机抽取一张图片,作为图片输入 # (2)取出该数据集下所有的标签,作为文字数据 image, class_id = cifar100[3637] image_input = preprocess(image).unsqueeze(0).to(device) text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) # 4、计算图像、文字的特征向量 # ------------------------------------------------- with torch.no_grad(): image_features = model.encode_image(image_input) text_features = model.encode_text(text_inputs) # 5、分别对图像、文字特征向量做归一化处理, # 然后计算余弦相似度 # 取最相似的top5结果 # ------------------------------------------------- image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) values, indices = similarity[0].topk(5) # 6、打印结果 print("\nTop predictions:\n") for value, index in zip(values, indices): print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
复制
import os import clip import torch from torchvision.datasets import CIFAR100 # 1、读取模型 device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load('ViT-B/32', device) # 2、下载数据集 cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False) # 3、(1)从数据集中随机抽取一张图片,作为图片输入 # (2)取出该数据集下所有的标签,作为文字数据 image, class_id = cifar100[3637] image_input = preprocess(image).unsqueeze(0).to(device) text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) # 4、计算图像、文字的特征向量 # ------------------------------------------------- with torch.no_grad(): image_features = model.encode_image(image_input) text_features = model.encode_text(text_inputs) # 5、分别对图像、文字特征向量做归一化处理, # 然后计算余弦相似度 # 取最相似的top5结果 # ------------------------------------------------- image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) values, indices = similarity[0].topk(5) # 6、打印结果 print("\nTop predictions:\n") for value, index in zip(values, indices): print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
复制
复制
复制
import os import clip import torch from torchvision.datasets import CIFAR100 # 1、读取模型 device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load('ViT-B/32', device) # 2、下载数据集 cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False) # 3、(1)从数据集中随机抽取一张图片,作为图片输入 # (2)取出该数据集下所有的标签,作为文字数据 image, class_id = cifar100[3637] image_input = preprocess(image).unsqueeze(0).to(device) text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) # 4、计算图像、文字的特征向量 # ------------------------------------------------- with torch.no_grad(): image_features = model.encode_image(image_input) text_features = model.encode_text(text_inputs) # 5、分别对图像、文字特征向量做归一化处理, # 然后计算余弦相似度 # 取最相似的top5结果 # ------------------------------------------------- image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) values, indices = similarity[0].topk(5) # 6、打印结果 print("\nTop predictions:\n") for value, index in zip(values, indices): print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
import os import clip import torch from torchvision.datasets import CIFAR100 # 1、读取模型 device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load('ViT-B/32', device) # 2、下载数据集 cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False) # 3、(1)从数据集中随机抽取一张图片,作为图片输入 # (2)取出该数据集下所有的标签,作为文字数据 image, class_id = cifar100[3637] image_input = preprocess(image).unsqueeze(0).to(device) text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) # 4、计算图像、文字的特征向量 # ------------------------------------------------- with torch.no_grad(): image_features = model.encode_image(image_input) text_features = model.encode_text(text_inputs) # 5、分别对图像、文字特征向量做归一化处理, # 然后计算余弦相似度 # 取最相似的top5结果 # ------------------------------------------------- image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) values, indices = similarity[0].topk(5) # 6、打印结果 print("\nTop predictions:\n") for value, index in zip(values, indices): print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
复制
import os import clip import torch from torchvision.datasets import CIFAR100 # 1、读取模型 device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load('ViT-B/32', device) # 2、下载数据集 cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False) # 3、(1)从数据集中随机抽取一张图片,作为图片输入 # (2)取出该数据集下所有的标签,作为文字数据 image, class_id = cifar100[3637] image_input = preprocess(image).unsqueeze(0).to(device) text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) # 4、计算图像、文字的特征向量 # ------------------------------------------------- with torch.no_grad(): image_features = model.encode_image(image_input) text_features = model.encode_text(text_inputs) # 5、分别对图像、文字特征向量做归一化处理, # 然后计算余弦相似度 # 取最相似的top5结果 # ------------------------------------------------- image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) values, indices = similarity[0].topk(5) # 6、打印结果 print("\nTop predictions:\n") for value, index in zip(values, indices): print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
import os import clip import torch from torchvision.datasets import CIFAR100 # 1、读取模型 device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load('ViT-B/32', device) # 2、下载数据集 cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False) # 3、(1)从数据集中随机抽取一张图片,作为图片输入 # (2)取出该数据集下所有的标签,作为文字数据 image, class_id = cifar100[3637] image_input = preprocess(image).unsqueeze(0).to(device) text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) # 4、计算图像、文字的特征向量 # ------------------------------------------------- with torch.no_grad(): image_features = model.encode_image(image_input) text_features = model.encode_text(text_inputs) # 5、分别对图像、文字特征向量做归一化处理, # 然后计算余弦相似度 # 取最相似的top5结果 # ------------------------------------------------- image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) values, indices = similarity[0].topk(5) # 6、打印结果 print("\nTop predictions:\n") for value, index in zip(values, indices): print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
复制
import os import clip import torch from torchvision.datasets import CIFAR100 # 1、读取模型 device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load('ViT-B/32', device) # 2、下载数据集 cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False) # 3、(1)从数据集中随机抽取一张图片,作为图片输入 # (2)取出该数据集下所有的标签,作为文字数据 image, class_id = cifar100[3637] image_input = preprocess(image).unsqueeze(0).to(device) text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) # 4、计算图像、文字的特征向量 # ------------------------------------------------- with torch.no_grad(): image_features = model.encode_image(image_input) text_features = model.encode_text(text_inputs) # 5、分别对图像、文字特征向量做归一化处理, # 然后计算余弦相似度 # 取最相似的top5结果 # ------------------------------------------------- image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) values, indices = similarity[0].topk(5) # 6、打印结果 print("\nTop predictions:\n") for value, index in zip(values, indices): print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
复制
复制
复制
问题:1.clip在与clip训练集有严重偏移的测试集效果一般。2.clip在prompt engineering这一步利用有限分类封闭的物体标签集合,在zero-shot测试集测试时对没有的标签无法预测新的文字标签。3.无法完成图像-文本的生成式网络任务(根据用户提供的文本描述自动生成对应的图像)解决:DALLE2,Stable Diffusion扩散模型。
VLMo:22年微软,统一的视觉语言预训练模型,通过所设计的模态混合专家(MOME)来捕获特定模态的信息,灵活改变模型结构来适应不同任务。
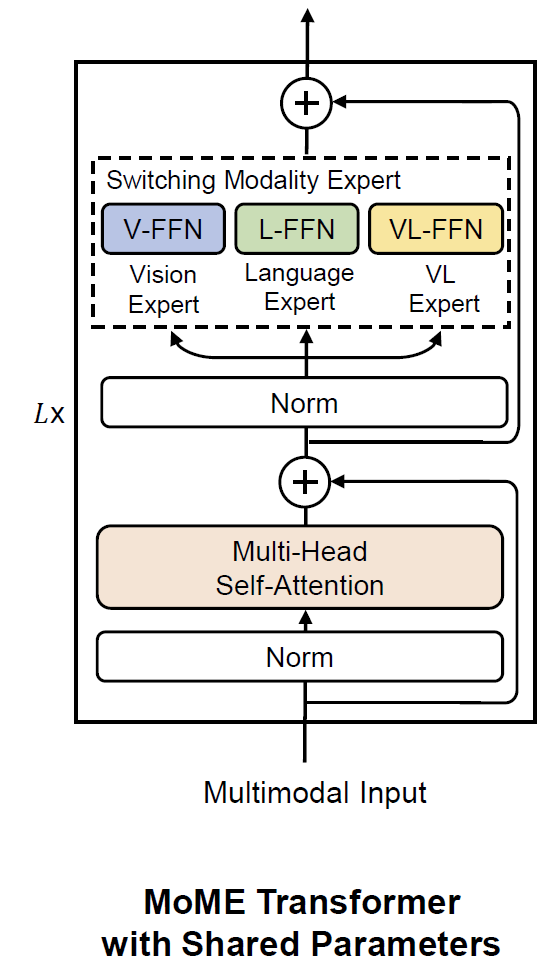
流程:1.对纯图像和纯文本进行预训练;2.进行多模态数据训练(Finetune)对比学习任务、图文匹配任务、掩码语言模型。
MetaLM:22年微软,语言模型作为通用接口。MetaLM提出了将语言模型作为基底、其他模态作为一种特殊编码的统一建模方式。Language models are general-purpose interfaces提出了一种使用语言模型作为各种基础模型的通用接口的方法。步骤:1.使用预训练的编码器来感知多模态(如视觉和语言);2.与扮演通用任务层角色的语言模型对接。
KOSMOS-1:微软23年2月。《Language is not all you need》KOSMOS-1 遵循LLM的自回归模型的研究范式,自然语言充当模态融合的媒介。可以流畅地回答各种问题,乃至完成智商测试。
数据集:1.单模态数据。如单纯的文本、图像等 GitHub, arXiv, Stack Exchange, PubMed Central。2.多模态成对数据。如图像和它的标题组成的图像-文本对 LAION-2B、LAION-400M、COYO-700M 和 Conceptual Captions。3.交叉的多模态数据。如从网页中爬取的嵌有图片的文档 71M web pages from the original 2B web pages
二、机器人具身感知决策方向论文
多模态有监督+真实环境测试。
LM-Nav: 在大规模数据集上进行预训练,使得机器人能够从大量的语言、视觉和动作数据中学习。将语言、视觉和动作模型结合在一起,语言模型用于理解人类指令和环境描述,视觉模型用于感知环境中的物体和场景,动作模型用于规划和执行机器人的移动动作。通过与环境的交互,能够学习到合适的动作策略,并根据奖励信号进行优化和调整。
https://sites.google.com/view/lmnav 2022年7月26日Google发布的第一篇应用大模型进行机器人导航的工作。流程:1.建离线地图:使用Vision-Navigation Model(VNM)创建拓扑地图->由人控制机器人进行环境探索(机器人先实地过一遍图),将图片作为拓扑地图的节点->用Traversability函数(通过学习节点间时间步数给出权重)赋予边的(节点间)权重。2.LLM将人类的自然语言指令解析为一个地标的文本序列(如车、路标、左拐等)。3.VLM根据地标文本信息匹配对应的图片。4.导航:(1)规划:地图搜索->需经过的图片路标(当前位置到目标点)(2)控制:根据 节点间图片+(里程计)节点间相对位姿->预测机器人位置和任一拓扑地图节点间的位姿->里程计和PD控制器控制移动到下一节点。
问题:1.性能:传感器使用单个RGB相机,单线激光雷达,轮式里程计。2.多模态:除了RGB图像外,IMU,单线激光雷达,GPS等数据均未参与多模态模型训练。3.架构:直接使用节点的图像学习相对位姿。
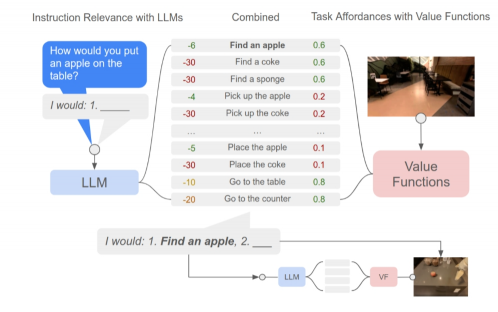
Saycan:预训练(机器人)低级技能+LLM高级语义知识,将来自LLM语言模型的概率(表示技能对指令有用的概率)与来自值函数的概率(表示成功执行所述技能的概率)结合起来,输出选择要执行的操作。(开源了仿真环境下的代码)。
创新点:LLM+预训练技能(真实环境的约束和可行性),将高级语义知识与实际环境联系起来,完成复杂和时间跨度较长的指令。指令可解释性+决策过程可视化。步骤:对话交互的形式重复调用模型。1.用户提问题。2.LLM query得到一些动作及其相关性+value function(利用TD传播来训练)输出动作可行性。3.执行(Policy机器人的手,通过强化学习(RL)和行为克隆(BC)方法训练)动作后接着问LLM下一步操作,直至结束。
不足:1.依赖于语言模型(局限性)的训练数据。2.模型的性能受限于(机器人)底层控制技能的范围和能力(鲁棒性)。3.当开展技能失败时,模型偶尔不做出反应。4.(因为继承底层语言模型)在处理否定语句和模糊引用等方面存在困难。改进:1.引入更多的现实环境约束(eg.环境反馈、人类反馈等)和引导。2.扩展机器人技能(更多场景)的范围和鲁棒性。3.提高语言模型对真实世界环境和物理规律的理解和推理能力。
VLM: 视觉语言模型(VLM)在视觉问答和图像字幕等任务上效果较好,但在理解常见物体的物理概念(例如材料、脆弱性、重量密度、软硬)方面存在局限性,不擅长处理涉及与这些物体交互和进行物理推理的机器人操作任务中。Physically Grounded Vision-Language Models for RoboticManipulation提出了PhysObjects-由39.6K人工标注数据和417K自动化物理概念标注的数据集。https://iliad.stanford.edu/pg-vlm/
VIMA: General Robot Manipulation with Multimodal Prompts 原始版的palm-e,将视觉和语言输入结合在具体机器人环境中直接预测动作(palm-e生成高级指令文本,有条件约束,原始离线地图知识,可做机器人推理和问答)。
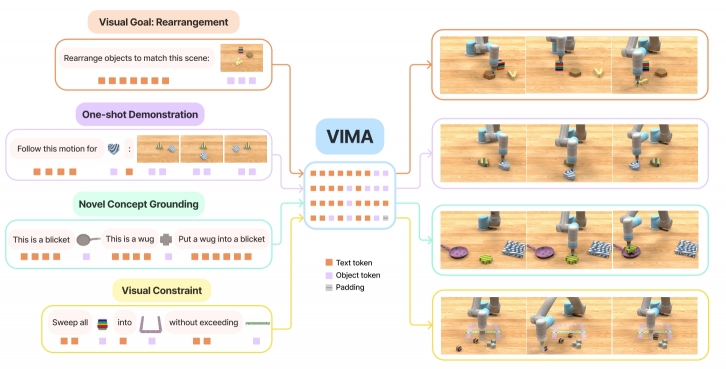
步骤:1.输入:输入一个包含文本和图像或视频帧的输入序列(多模态提示序列(multimodal prompts))。
#输入序列由交替的文本和视觉提示令牌组成,通过预训练的语言模型(如T5模型)进行编码
class T5EncoderModel(T5PreTrainedModel):
authorized_missing_keys = [
r"encoder.embed_tokens.weight",
]
def __init__(self, config):
super().__init__(config)
self.shared = nn.Embedding(config.vocab_size, config.d_model)
encoder_config = copy.deepcopy(config)
encoder_config.use_cache = False
encoder_config.is_encoder_decoder = False
self.encoder = T5Stack(encoder_config, self.shared)
# Initialize weights and apply final processing初始化权重并应用到编解码阶段
self.post_init()
# Model parallel模型分布式计算
self.model_parallel = False
self.device_map = None
#Prompt Encoder步骤中使用T5模型对文本输入进行编码
class WordEmbedding(nn.Module):
def __init__(self):
super().__init__()
model = AutoModel.from_pretrained("t5-base")
embed_weight = model.get_input_embeddings().weight.data
_emb_dim = embed_weight.shape[1]
self._embed_layer = nn.Embedding.from_pretrained(embed_weight)
del model
self.output_dim = _emb_dim
#输入序列由交替的文本和视觉提示令牌组成,通过预训练的语言模型(如T5模型)进行编码 class T5EncoderModel(T5PreTrainedModel): authorized_missing_keys = [ r"encoder.embed_tokens.weight", ] def __init__(self, config): super().__init__(config) self.shared = nn.Embedding(config.vocab_size, config.d_model) encoder_config = copy.deepcopy(config) encoder_config.use_cache = False encoder_config.is_encoder_decoder = False self.encoder = T5Stack(encoder_config, self.shared) # Initialize weights and apply final processing初始化权重并应用到编解码阶段 self.post_init() # Model parallel模型分布式计算 self.model_parallel = False self.device_map = None #Prompt Encoder步骤中使用T5模型对文本输入进行编码 class WordEmbedding(nn.Module): def __init__(self): super().__init__() model = AutoModel.from_pretrained("t5-base") embed_weight = model.get_input_embeddings().weight.data _emb_dim = embed_weight.shape[1] self._embed_layer = nn.Embedding.from_pretrained(embed_weight) del model self.output_dim = _emb_dim
#输入序列由交替的文本和视觉提示令牌组成,通过预训练的语言模型(如T5模型)进行编码 class T5EncoderModel(T5PreTrainedModel): authorized_missing_keys = [ r"encoder.embed_tokens.weight", ] def __init__(self, config): super().__init__(config) self.shared = nn.Embedding(config.vocab_size, config.d_model) encoder_config = copy.deepcopy(config) encoder_config.use_cache = False encoder_config.is_encoder_decoder = False self.encoder = T5Stack(encoder_config, self.shared) # Initialize weights and apply final processing初始化权重并应用到编解码阶段 self.post_init() # Model parallel模型分布式计算 self.model_parallel = False self.device_map = None #Prompt Encoder步骤中使用T5模型对文本输入进行编码 class WordEmbedding(nn.Module): def __init__(self): super().__init__() model = AutoModel.from_pretrained("t5-base") embed_weight = model.get_input_embeddings().weight.data _emb_dim = embed_weight.shape[1] self._embed_layer = nn.Embedding.from_pretrained(embed_weight) del model self.output_dim = _emb_dim
复制
#输入序列由交替的文本和视觉提示令牌组成,通过预训练的语言模型(如T5模型)进行编码 class T5EncoderModel(T5PreTrainedModel): authorized_missing_keys = [ r"encoder.embed_tokens.weight", ] def __init__(self, config): super().__init__(config) self.shared = nn.Embedding(config.vocab_size, config.d_model) encoder_config = copy.deepcopy(config) encoder_config.use_cache = False encoder_config.is_encoder_decoder = False self.encoder = T5Stack(encoder_config, self.shared) # Initialize weights and apply final processing初始化权重并应用到编解码阶段 self.post_init() # Model parallel模型分布式计算 self.model_parallel = False self.device_map = None #Prompt Encoder步骤中使用T5模型对文本输入进行编码 class WordEmbedding(nn.Module): def __init__(self): super().__init__() model = AutoModel.from_pretrained("t5-base") embed_weight = model.get_input_embeddings().weight.data _emb_dim = embed_weight.shape[1] self._embed_layer = nn.Embedding.from_pretrained(embed_weight) del model self.output_dim = _emb_dim
#输入序列由交替的文本和视觉提示令牌组成,通过预训练的语言模型(如T5模型)进行编码 class T5EncoderModel(T5PreTrainedModel): authorized_missing_keys = [ r"encoder.embed_tokens.weight", ] def __init__(self, config): super().__init__(config) self.shared = nn.Embedding(config.vocab_size, config.d_model) encoder_config = copy.deepcopy(config) encoder_config.use_cache = False encoder_config.is_encoder_decoder = False self.encoder = T5Stack(encoder_config, self.shared) # Initialize weights and apply final processing初始化权重并应用到编解码阶段 self.post_init() # Model parallel模型分布式计算 self.model_parallel = False self.device_map = None #Prompt Encoder步骤中使用T5模型对文本输入进行编码 class WordEmbedding(nn.Module): def __init__(self): super().__init__() model = AutoModel.from_pretrained("t5-base") embed_weight = model.get_input_embeddings().weight.data _emb_dim = embed_weight.shape[1] self._embed_layer = nn.Embedding.from_pretrained(embed_weight) del model self.output_dim = _emb_dim
复制
#输入序列由交替的文本和视觉提示令牌组成,通过预训练的语言模型(如T5模型)进行编码 class T5EncoderModel(T5PreTrainedModel): authorized_missing_keys = [ r"encoder.embed_tokens.weight", ] def __init__(self, config): super().__init__(config) self.shared = nn.Embedding(config.vocab_size, config.d_model) encoder_config = copy.deepcopy(config) encoder_config.use_cache = False encoder_config.is_encoder_decoder = False self.encoder = T5Stack(encoder_config, self.shared) # Initialize weights and apply final processing初始化权重并应用到编解码阶段 self.post_init() # Model parallel模型分布式计算 self.model_parallel = False self.device_map = None #Prompt Encoder步骤中使用T5模型对文本输入进行编码 class WordEmbedding(nn.Module): def __init__(self): super().__init__() model = AutoModel.from_pretrained("t5-base") embed_weight = model.get_input_embeddings().weight.data _emb_dim = embed_weight.shape[1] self._embed_layer = nn.Embedding.from_pretrained(embed_weight) del model self.output_dim = _emb_dim
#输入序列由交替的文本和视觉提示令牌组成,通过预训练的语言模型(如T5模型)进行编码 class T5EncoderModel(T5PreTrainedModel): authorized_missing_keys = [ r"encoder.embed_tokens.weight", ] def __init__(self, config): super().__init__(config) self.shared = nn.Embedding(config.vocab_size, config.d_model) encoder_config = copy.deepcopy(config) encoder_config.use_cache = False encoder_config.is_encoder_decoder = False self.encoder = T5Stack(encoder_config, self.shared) # Initialize weights and apply final processing初始化权重并应用到编解码阶段 self.post_init() # Model parallel模型分布式计算 self.model_parallel = False self.device_map = None #Prompt Encoder步骤中使用T5模型对文本输入进行编码 class WordEmbedding(nn.Module): def __init__(self): super().__init__() model = AutoModel.from_pretrained("t5-base") embed_weight = model.get_input_embeddings().weight.data _emb_dim = embed_weight.shape[1] self._embed_layer = nn.Embedding.from_pretrained(embed_weight) del model self.output_dim = _emb_dim
#输入序列由交替的文本和视觉提示令牌组成,通过预训练的语言模型(如T5模型)进行编码 class T5EncoderModel(T5PreTrainedModel): authorized_missing_keys = [ r"encoder.embed_tokens.weight", ] def __init__(self, config): super().__init__(config) self.shared = nn.Embedding(config.vocab_size, config.d_model) encoder_config = copy.deepcopy(config) encoder_config.use_cache = False encoder_config.is_encoder_decoder = False self.encoder = T5Stack(encoder_config, self.shared) # Initialize weights and apply final processing初始化权重并应用到编解码阶段 self.post_init() # Model parallel模型分布式计算 self.model_parallel = False self.device_map = None #Prompt Encoder步骤中使用T5模型对文本输入进行编码 class WordEmbedding(nn.Module): def __init__(self): super().__init__() model = AutoModel.from_pretrained("t5-base") embed_weight = model.get_input_embeddings().weight.data _emb_dim = embed_weight.shape[1] self._embed_layer = nn.Embedding.from_pretrained(embed_weight) del model self.output_dim = _emb_dim
复制
#输入序列由交替的文本和视觉提示令牌组成,通过预训练的语言模型(如T5模型)进行编码 class T5EncoderModel(T5PreTrainedModel): authorized_missing_keys = [ r"encoder.embed_tokens.weight", ] def __init__(self, config): super().__init__(config) self.shared = nn.Embedding(config.vocab_size, config.d_model) encoder_config = copy.deepcopy(config) encoder_config.use_cache = False encoder_config.is_encoder_decoder = False self.encoder = T5Stack(encoder_config, self.shared) # Initialize weights and apply final processing初始化权重并应用到编解码阶段 self.post_init() # Model parallel模型分布式计算 self.model_parallel = False self.device_map = None #Prompt Encoder步骤中使用T5模型对文本输入进行编码 class WordEmbedding(nn.Module): def __init__(self): super().__init__() model = AutoModel.from_pretrained("t5-base") embed_weight = model.get_input_embeddings().weight.data _emb_dim = embed_weight.shape[1] self._embed_layer = nn.Embedding.from_pretrained(embed_weight) del model self.output_dim = _emb_dim
#输入序列由交替的文本和视觉提示令牌组成,通过预训练的语言模型(如T5模型)进行编码 class T5EncoderModel(T5PreTrainedModel): authorized_missing_keys = [ r"encoder.embed_tokens.weight", ] def __init__(self, config): super().__init__(config) self.shared = nn.Embedding(config.vocab_size, config.d_model) encoder_config = copy.deepcopy(config) encoder_config.use_cache = False encoder_config.is_encoder_decoder = False self.encoder = T5Stack(encoder_config, self.shared) # Initialize weights and apply final processing初始化权重并应用到编解码阶段 self.post_init() # Model parallel模型分布式计算 self.model_parallel = False self.device_map = None #Prompt Encoder步骤中使用T5模型对文本输入进行编码 class WordEmbedding(nn.Module): def __init__(self): super().__init__() model = AutoModel.from_pretrained("t5-base") embed_weight = model.get_input_embeddings().weight.data _emb_dim = embed_weight.shape[1] self._embed_layer = nn.Embedding.from_pretrained(embed_weight) del model self.output_dim = _emb_dim
复制
#输入序列由交替的文本和视觉提示令牌组成,通过预训练的语言模型(如T5模型)进行编码 class T5EncoderModel(T5PreTrainedModel): authorized_missing_keys = [ r"encoder.embed_tokens.weight", ] def __init__(self, config): super().__init__(config) self.shared = nn.Embedding(config.vocab_size, config.d_model) encoder_config = copy.deepcopy(config) encoder_config.use_cache = False encoder_config.is_encoder_decoder = False self.encoder = T5Stack(encoder_config, self.shared) # Initialize weights and apply final processing初始化权重并应用到编解码阶段 self.post_init() # Model parallel模型分布式计算 self.model_parallel = False self.device_map = None #Prompt Encoder步骤中使用T5模型对文本输入进行编码 class WordEmbedding(nn.Module): def __init__(self): super().__init__() model = AutoModel.from_pretrained("t5-base") embed_weight = model.get_input_embeddings().weight.data _emb_dim = embed_weight.shape[1] self._embed_layer = nn.Embedding.from_pretrained(embed_weight) del model self.output_dim = _emb_dim
复制
复制
复制
2.Transformer 编码:输入序列编码,将文本和图像信息转换为表示向量(序列建模)。序列建模:学习提示序列中的语言和视觉信息之间的关联来理解任务规范。解码:表示向量输入到解码器中生成对应的输出(eg操作指令序列)。
#1.编码:将视觉提示中的物体信息和多个视角的RGB图像编码为嵌入向量表示,以供后续的序列建模和决策生成步骤使用,包含ObjEncoder,GatoMultiViewRGBEncoder, MultiViewRGBPerceiverEncoder, MultiViewRGBEncoder四部分,实际使用的是vit模型。
#ObjEncoder部分,将输入的物体图像或特征提取为物体的表示
self.cropped_img_encoder = ViTEncoder(
output_dim=vit_output_dim,
resolution=vit_resolution,
patch_size=vit_patch_size,
width=vit_width,
layers=vit_layers,
heads=vit_heads,
)
#GatoMultiViewRGBEncoder:多视角RGB编码器,用于对多个视角的RGB图像进行编码转换为嵌入向量表示。
#MultiViewRGBPerceiverEncoder:多视角RGB Perceiver编码器。Perceiver是一种结合了注意力机制和卷积操作的神经网络结构,用于处理结构化输入和输出。
#MultiViewRGBEncoder:一个多视角RGB编码器,用于对多个视角的RGB图像进行编码。
#2.(基于GPT的序列建模方法)序列建模,包含引入OpenAIGPTPreTrainedModel(gpt预训练模型)和XAttnGPT、HFGPT三部分。学习输入序列的语义表示和序列之间的关联,从而生成合理的机器人动作序列。
from transformers.models.openai.modeling_openai import (
OpenAIGPTPreTrainedModel,
OpenAIGPTConfig,
)
#gpt
def __init__(self, config):
super().__init__(config)
self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd)
self.positions_embed = nn.Embedding(config.n_positions, config.n_embd)
self.drop = nn.Dropout(config.embd_pdrop)
self.h = nn.ModuleList(
[
Block(config.n_positions, config, scale=True)
for _ in range(config.n_layer)
]
)
self.register_buffer("position_ids", torch.arange(config.n_positions))
# 初始化权重并应用到编解码阶段
self.post_init()
#XAttn表示交叉注意力(Cross-Attention),对输入的提示序列和历史交互序列进行编码,并通过交叉注意力机制将提示序列与历史交互序列进行关联。这样,模型可以在生成下一步动作时考虑到提示信息和先前的交互历史。
class XAttnGPT(OpenAIGPTPreTrainedModel):
def __init__(
self,
embd_dim: int = 768,
*,
n_positions: int = 512,
n_layer: int = 12,
n_head: int = 12,
dropout: float = 0.1,
xattn_n_head: int = 8,
xattn_ff_expanding: int = 4,
xattn_detach_qk: bool = False,
xattn_n_positions: int,
use_geglu: bool = False,
):
#HFGPT(历史注意力)在生成下一步动作时主要关注历史交互序列,而不是提示序列。使用GPT对历史交互序列进行编码,并通过自注意力机制(Self-Attention)捕捉序列中的上下文信息,以生成下一步动作。
class HFGPT(nn.Module) #略
#3.解码:Action Embedding(动作嵌入):将机器人的动作编码为嵌入向量,包含ActionEmbedding, ContinuousActionEmbedding两部分。ActionEmbedding将机器人的离散动作符号(如"pick and place"或"wipe")转换为嵌入向量(如使用整数编码),以便模型能够对其进行处理和预测。这种嵌入表示可以捕捉到不同动作之间的语义关系和相似性。
class ActionEmbedding(nn.Module):
def __init__(self, output_dim: int, *, embed_dict: dict[str, nn.Module]):
super().__init__()
self._embed_dict = nn.ModuleDict(embed_dict)
embed_dict_output_dim = sum(
embed_dict[k].output_dim for k in sorted(embed_dict.keys())
)
self._post_layer = (
nn.Identity()
if output_dim == embed_dict_output_dim
else nn.Linear(embed_dict_output_dim, output_dim)
)
self._output_dim = output_dim
self._input_fields_checked = False
#ContinuousActionEmbedding:将机器人的连续动作(通常由一组连续的数值表示,如机器人臂的位置和姿态)转换为嵌入向量,可以捕捉到不同连续动作之间的关系和变化。
class ContinuousActionEmbedding(nn.Module): #略
#Action Decoder(动作解码器):使用解码器部分生成机器人的动作序列。创建一个包含多个解码器的模块字典用于将神经网络输出转换为对应的动作。参数action_dims表示每个动作的维度,可以是一个整数(用CategoricalNet解码)或一个整数列表(用MultiCategoricalNet解码)。
self._decoders = nn.ModuleDict()
for k, v in action_dims.items():
if isinstance(v, int):
self._decoders[k] = CategoricalNet(
#略
)
elif isinstance(v, list):
self._decoders[k] = MultiCategoricalNet(
input_dim,
action_dims=v,
hidden_dim=hidden_dim,
hidden_depth=hidden_depth,
activation=activation,
norm_type=norm_type,
last_layer_gain=last_layer_gain,
)
else:
raise ValueError(f"Invalid action_dims value: {v}")
class MultiCategoricalNet(nn.Module):
def __init__(
self,
input_dim: int, #接收输入维度
*,
action_dims: list[int], #动作维度列表
hidden_dim: int, #隐藏层维度
hidden_depth: int,
activation: str | Callable = "relu",
norm_type: Literal["batchnorm", "layernorm"] | None = None,
last_layer_gain: float | None = 0.01, #最后一层初始化增益
):
super().__init__() #调用父类的初始化函数
self.mlps = nn.ModuleList() #创建一个空的nn.ModuleList存储多个MLP感知网络
for action in action_dims: #遍历动作维度列表
net = _build_mlp_distribution_net( #构建MLP分布网络
#略
)
self.mlps.append(net)
self.head = MultiCategoricalHead(action_dims)#创建一个MultiCategoricalHead对象传入动作维度列表
#1.编码:将视觉提示中的物体信息和多个视角的RGB图像编码为嵌入向量表示,以供后续的序列建模和决策生成步骤使用,包含ObjEncoder,GatoMultiViewRGBEncoder, MultiViewRGBPerceiverEncoder, MultiViewRGBEncoder四部分,实际使用的是vit模型。 #ObjEncoder部分,将输入的物体图像或特征提取为物体的表示 self.cropped_img_encoder = ViTEncoder( output_dim=vit_output_dim, resolution=vit_resolution, patch_size=vit_patch_size, width=vit_width, layers=vit_layers, heads=vit_heads, ) #GatoMultiViewRGBEncoder:多视角RGB编码器,用于对多个视角的RGB图像进行编码转换为嵌入向量表示。 #MultiViewRGBPerceiverEncoder:多视角RGB Perceiver编码器。Perceiver是一种结合了注意力机制和卷积操作的神经网络结构,用于处理结构化输入和输出。 #MultiViewRGBEncoder:一个多视角RGB编码器,用于对多个视角的RGB图像进行编码。 #2.(基于GPT的序列建模方法)序列建模,包含引入OpenAIGPTPreTrainedModel(gpt预训练模型)和XAttnGPT、HFGPT三部分。学习输入序列的语义表示和序列之间的关联,从而生成合理的机器人动作序列。 from transformers.models.openai.modeling_openai import ( OpenAIGPTPreTrainedModel, OpenAIGPTConfig, ) #gpt def __init__(self, config): super().__init__(config) self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd) self.positions_embed = nn.Embedding(config.n_positions, config.n_embd) self.drop = nn.Dropout(config.embd_pdrop) self.h = nn.ModuleList( [ Block(config.n_positions, config, scale=True) for _ in range(config.n_layer) ] ) self.register_buffer("position_ids", torch.arange(config.n_positions)) # 初始化权重并应用到编解码阶段 self.post_init() #XAttn表示交叉注意力(Cross-Attention),对输入的提示序列和历史交互序列进行编码,并通过交叉注意力机制将提示序列与历史交互序列进行关联。这样,模型可以在生成下一步动作时考虑到提示信息和先前的交互历史。 class XAttnGPT(OpenAIGPTPreTrainedModel): def __init__( self, embd_dim: int = 768, *, n_positions: int = 512, n_layer: int = 12, n_head: int = 12, dropout: float = 0.1, xattn_n_head: int = 8, xattn_ff_expanding: int = 4, xattn_detach_qk: bool = False, xattn_n_positions: int, use_geglu: bool = False, ): #HFGPT(历史注意力)在生成下一步动作时主要关注历史交互序列,而不是提示序列。使用GPT对历史交互序列进行编码,并通过自注意力机制(Self-Attention)捕捉序列中的上下文信息,以生成下一步动作。 class HFGPT(nn.Module) #略 #3.解码:Action Embedding(动作嵌入):将机器人的动作编码为嵌入向量,包含ActionEmbedding, ContinuousActionEmbedding两部分。ActionEmbedding将机器人的离散动作符号(如"pick and place"或"wipe")转换为嵌入向量(如使用整数编码),以便模型能够对其进行处理和预测。这种嵌入表示可以捕捉到不同动作之间的语义关系和相似性。 class ActionEmbedding(nn.Module): def __init__(self, output_dim: int, *, embed_dict: dict[str, nn.Module]): super().__init__() self._embed_dict = nn.ModuleDict(embed_dict) embed_dict_output_dim = sum( embed_dict[k].output_dim for k in sorted(embed_dict.keys()) ) self._post_layer = ( nn.Identity() if output_dim == embed_dict_output_dim else nn.Linear(embed_dict_output_dim, output_dim) ) self._output_dim = output_dim self._input_fields_checked = False #ContinuousActionEmbedding:将机器人的连续动作(通常由一组连续的数值表示,如机器人臂的位置和姿态)转换为嵌入向量,可以捕捉到不同连续动作之间的关系和变化。 class ContinuousActionEmbedding(nn.Module): #略 #Action Decoder(动作解码器):使用解码器部分生成机器人的动作序列。创建一个包含多个解码器的模块字典用于将神经网络输出转换为对应的动作。参数action_dims表示每个动作的维度,可以是一个整数(用CategoricalNet解码)或一个整数列表(用MultiCategoricalNet解码)。 self._decoders = nn.ModuleDict() for k, v in action_dims.items(): if isinstance(v, int): self._decoders[k] = CategoricalNet( #略 ) elif isinstance(v, list): self._decoders[k] = MultiCategoricalNet( input_dim, action_dims=v, hidden_dim=hidden_dim, hidden_depth=hidden_depth, activation=activation, norm_type=norm_type, last_layer_gain=last_layer_gain, ) else: raise ValueError(f"Invalid action_dims value: {v}") class MultiCategoricalNet(nn.Module): def __init__( self, input_dim: int, #接收输入维度 *, action_dims: list[int], #动作维度列表 hidden_dim: int, #隐藏层维度 hidden_depth: int, activation: str | Callable = "relu", norm_type: Literal["batchnorm", "layernorm"] | None = None, last_layer_gain: float | None = 0.01, #最后一层初始化增益 ): super().__init__() #调用父类的初始化函数 self.mlps = nn.ModuleList() #创建一个空的nn.ModuleList存储多个MLP感知网络 for action in action_dims: #遍历动作维度列表 net = _build_mlp_distribution_net( #构建MLP分布网络 #略 ) self.mlps.append(net) self.head = MultiCategoricalHead(action_dims)#创建一个MultiCategoricalHead对象传入动作维度列表
#1.编码:将视觉提示中的物体信息和多个视角的RGB图像编码为嵌入向量表示,以供后续的序列建模和决策生成步骤使用,包含ObjEncoder,GatoMultiViewRGBEncoder, MultiViewRGBPerceiverEncoder, MultiViewRGBEncoder四部分,实际使用的是vit模型。 #ObjEncoder部分,将输入的物体图像或特征提取为物体的表示 self.cropped_img_encoder = ViTEncoder( output_dim=vit_output_dim, resolution=vit_resolution, patch_size=vit_patch_size, width=vit_width, layers=vit_layers, heads=vit_heads, ) #GatoMultiViewRGBEncoder:多视角RGB编码器,用于对多个视角的RGB图像进行编码转换为嵌入向量表示。 #MultiViewRGBPerceiverEncoder:多视角RGB Perceiver编码器。Perceiver是一种结合了注意力机制和卷积操作的神经网络结构,用于处理结构化输入和输出。 #MultiViewRGBEncoder:一个多视角RGB编码器,用于对多个视角的RGB图像进行编码。 #2.(基于GPT的序列建模方法)序列建模,包含引入OpenAIGPTPreTrainedModel(gpt预训练模型)和XAttnGPT、HFGPT三部分。学习输入序列的语义表示和序列之间的关联,从而生成合理的机器人动作序列。 from transformers.models.openai.modeling_openai import ( OpenAIGPTPreTrainedModel, OpenAIGPTConfig, ) #gpt def __init__(self, config): super().__init__(config) self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd) self.positions_embed = nn.Embedding(config.n_positions, config.n_embd) self.drop = nn.Dropout(config.embd_pdrop) self.h = nn.ModuleList( [ Block(config.n_positions, config, scale=True) for _ in range(config.n_layer) ] ) self.register_buffer("position_ids", torch.arange(config.n_positions)) # 初始化权重并应用到编解码阶段 self.post_init() #XAttn表示交叉注意力(Cross-Attention),对输入的提示序列和历史交互序列进行编码,并通过交叉注意力机制将提示序列与历史交互序列进行关联。这样,模型可以在生成下一步动作时考虑到提示信息和先前的交互历史。 class XAttnGPT(OpenAIGPTPreTrainedModel): def __init__( self, embd_dim: int = 768, *, n_positions: int = 512, n_layer: int = 12, n_head: int = 12, dropout: float = 0.1, xattn_n_head: int = 8, xattn_ff_expanding: int = 4, xattn_detach_qk: bool = False, xattn_n_positions: int, use_geglu: bool = False, ): #HFGPT(历史注意力)在生成下一步动作时主要关注历史交互序列,而不是提示序列。使用GPT对历史交互序列进行编码,并通过自注意力机制(Self-Attention)捕捉序列中的上下文信息,以生成下一步动作。 class HFGPT(nn.Module) #略 #3.解码:Action Embedding(动作嵌入):将机器人的动作编码为嵌入向量,包含ActionEmbedding, ContinuousActionEmbedding两部分。ActionEmbedding将机器人的离散动作符号(如"pick and place"或"wipe")转换为嵌入向量(如使用整数编码),以便模型能够对其进行处理和预测。这种嵌入表示可以捕捉到不同动作之间的语义关系和相似性。 class ActionEmbedding(nn.Module): def __init__(self, output_dim: int, *, embed_dict: dict[str, nn.Module]): super().__init__() self._embed_dict = nn.ModuleDict(embed_dict) embed_dict_output_dim = sum( embed_dict[k].output_dim for k in sorted(embed_dict.keys()) ) self._post_layer = ( nn.Identity() if output_dim == embed_dict_output_dim else nn.Linear(embed_dict_output_dim, output_dim) ) self._output_dim = output_dim self._input_fields_checked = False #ContinuousActionEmbedding:将机器人的连续动作(通常由一组连续的数值表示,如机器人臂的位置和姿态)转换为嵌入向量,可以捕捉到不同连续动作之间的关系和变化。 class ContinuousActionEmbedding(nn.Module): #略 #Action Decoder(动作解码器):使用解码器部分生成机器人的动作序列。创建一个包含多个解码器的模块字典用于将神经网络输出转换为对应的动作。参数action_dims表示每个动作的维度,可以是一个整数(用CategoricalNet解码)或一个整数列表(用MultiCategoricalNet解码)。 self._decoders = nn.ModuleDict() for k, v in action_dims.items(): if isinstance(v, int): self._decoders[k] = CategoricalNet( #略 ) elif isinstance(v, list): self._decoders[k] = MultiCategoricalNet( input_dim, action_dims=v, hidden_dim=hidden_dim, hidden_depth=hidden_depth, activation=activation, norm_type=norm_type, last_layer_gain=last_layer_gain, ) else: raise ValueError(f"Invalid action_dims value: {v}") class MultiCategoricalNet(nn.Module): def __init__( self, input_dim: int, #接收输入维度 *, action_dims: list[int], #动作维度列表 hidden_dim: int, #隐藏层维度 hidden_depth: int, activation: str | Callable = "relu", norm_type: Literal["batchnorm", "layernorm"] | None = None, last_layer_gain: float | None = 0.01, #最后一层初始化增益 ): super().__init__() #调用父类的初始化函数 self.mlps = nn.ModuleList() #创建一个空的nn.ModuleList存储多个MLP感知网络 for action in action_dims: #遍历动作维度列表 net = _build_mlp_distribution_net( #构建MLP分布网络 #略 ) self.mlps.append(net) self.head = MultiCategoricalHead(action_dims)#创建一个MultiCategoricalHead对象传入动作维度列表
复制
#1.编码:将视觉提示中的物体信息和多个视角的RGB图像编码为嵌入向量表示,以供后续的序列建模和决策生成步骤使用,包含ObjEncoder,GatoMultiViewRGBEncoder, MultiViewRGBPerceiverEncoder, MultiViewRGBEncoder四部分,实际使用的是vit模型。 #ObjEncoder部分,将输入的物体图像或特征提取为物体的表示 self.cropped_img_encoder = ViTEncoder( output_dim=vit_output_dim, resolution=vit_resolution, patch_size=vit_patch_size, width=vit_width, layers=vit_layers, heads=vit_heads, ) #GatoMultiViewRGBEncoder:多视角RGB编码器,用于对多个视角的RGB图像进行编码转换为嵌入向量表示。 #MultiViewRGBPerceiverEncoder:多视角RGB Perceiver编码器。Perceiver是一种结合了注意力机制和卷积操作的神经网络结构,用于处理结构化输入和输出。 #MultiViewRGBEncoder:一个多视角RGB编码器,用于对多个视角的RGB图像进行编码。 #2.(基于GPT的序列建模方法)序列建模,包含引入OpenAIGPTPreTrainedModel(gpt预训练模型)和XAttnGPT、HFGPT三部分。学习输入序列的语义表示和序列之间的关联,从而生成合理的机器人动作序列。 from transformers.models.openai.modeling_openai import ( OpenAIGPTPreTrainedModel, OpenAIGPTConfig, ) #gpt def __init__(self, config): super().__init__(config) self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd) self.positions_embed = nn.Embedding(config.n_positions, config.n_embd) self.drop = nn.Dropout(config.embd_pdrop) self.h = nn.ModuleList( [ Block(config.n_positions, config, scale=True) for _ in range(config.n_layer) ] ) self.register_buffer("position_ids", torch.arange(config.n_positions)) # 初始化权重并应用到编解码阶段 self.post_init() #XAttn表示交叉注意力(Cross-Attention),对输入的提示序列和历史交互序列进行编码,并通过交叉注意力机制将提示序列与历史交互序列进行关联。这样,模型可以在生成下一步动作时考虑到提示信息和先前的交互历史。 class XAttnGPT(OpenAIGPTPreTrainedModel): def __init__( self, embd_dim: int = 768, *, n_positions: int = 512, n_layer: int = 12, n_head: int = 12, dropout: float = 0.1, xattn_n_head: int = 8, xattn_ff_expanding: int = 4, xattn_detach_qk: bool = False, xattn_n_positions: int, use_geglu: bool = False, ): #HFGPT(历史注意力)在生成下一步动作时主要关注历史交互序列,而不是提示序列。使用GPT对历史交互序列进行编码,并通过自注意力机制(Self-Attention)捕捉序列中的上下文信息,以生成下一步动作。 class HFGPT(nn.Module) #略 #3.解码:Action Embedding(动作嵌入):将机器人的动作编码为嵌入向量,包含ActionEmbedding, ContinuousActionEmbedding两部分。ActionEmbedding将机器人的离散动作符号(如"pick and place"或"wipe")转换为嵌入向量(如使用整数编码),以便模型能够对其进行处理和预测。这种嵌入表示可以捕捉到不同动作之间的语义关系和相似性。 class ActionEmbedding(nn.Module): def __init__(self, output_dim: int, *, embed_dict: dict[str, nn.Module]): super().__init__() self._embed_dict = nn.ModuleDict(embed_dict) embed_dict_output_dim = sum( embed_dict[k].output_dim for k in sorted(embed_dict.keys()) ) self._post_layer = ( nn.Identity() if output_dim == embed_dict_output_dim else nn.Linear(embed_dict_output_dim, output_dim) ) self._output_dim = output_dim self._input_fields_checked = False #ContinuousActionEmbedding:将机器人的连续动作(通常由一组连续的数值表示,如机器人臂的位置和姿态)转换为嵌入向量,可以捕捉到不同连续动作之间的关系和变化。 class ContinuousActionEmbedding(nn.Module): #略 #Action Decoder(动作解码器):使用解码器部分生成机器人的动作序列。创建一个包含多个解码器的模块字典用于将神经网络输出转换为对应的动作。参数action_dims表示每个动作的维度,可以是一个整数(用CategoricalNet解码)或一个整数列表(用MultiCategoricalNet解码)。 self._decoders = nn.ModuleDict() for k, v in action_dims.items(): if isinstance(v, int): self._decoders[k] = CategoricalNet( #略 ) elif isinstance(v, list): self._decoders[k] = MultiCategoricalNet( input_dim, action_dims=v, hidden_dim=hidden_dim, hidden_depth=hidden_depth, activation=activation, norm_type=norm_type, last_layer_gain=last_layer_gain, ) else: raise ValueError(f"Invalid action_dims value: {v}") class MultiCategoricalNet(nn.Module): def __init__( self, input_dim: int, #接收输入维度 *, action_dims: list[int], #动作维度列表 hidden_dim: int, #隐藏层维度 hidden_depth: int, activation: str | Callable = "relu", norm_type: Literal["batchnorm", "layernorm"] | None = None, last_layer_gain: float | None = 0.01, #最后一层初始化增益 ): super().__init__() #调用父类的初始化函数 self.mlps = nn.ModuleList() #创建一个空的nn.ModuleList存储多个MLP感知网络 for action in action_dims: #遍历动作维度列表 net = _build_mlp_distribution_net( #构建MLP分布网络 #略 ) self.mlps.append(net) self.head = MultiCategoricalHead(action_dims)#创建一个MultiCategoricalHead对象传入动作维度列表
#1.编码:将视觉提示中的物体信息和多个视角的RGB图像编码为嵌入向量表示,以供后续的序列建模和决策生成步骤使用,包含ObjEncoder,GatoMultiViewRGBEncoder, MultiViewRGBPerceiverEncoder, MultiViewRGBEncoder四部分,实际使用的是vit模型。 #ObjEncoder部分,将输入的物体图像或特征提取为物体的表示 self.cropped_img_encoder = ViTEncoder( output_dim=vit_output_dim, resolution=vit_resolution, patch_size=vit_patch_size, width=vit_width, layers=vit_layers, heads=vit_heads, ) #GatoMultiViewRGBEncoder:多视角RGB编码器,用于对多个视角的RGB图像进行编码转换为嵌入向量表示。 #MultiViewRGBPerceiverEncoder:多视角RGB Perceiver编码器。Perceiver是一种结合了注意力机制和卷积操作的神经网络结构,用于处理结构化输入和输出。 #MultiViewRGBEncoder:一个多视角RGB编码器,用于对多个视角的RGB图像进行编码。 #2.(基于GPT的序列建模方法)序列建模,包含引入OpenAIGPTPreTrainedModel(gpt预训练模型)和XAttnGPT、HFGPT三部分。学习输入序列的语义表示和序列之间的关联,从而生成合理的机器人动作序列。 from transformers.models.openai.modeling_openai import ( OpenAIGPTPreTrainedModel, OpenAIGPTConfig, ) #gpt def __init__(self, config): super().__init__(config) self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd) self.positions_embed = nn.Embedding(config.n_positions, config.n_embd) self.drop = nn.Dropout(config.embd_pdrop) self.h = nn.ModuleList( [ Block(config.n_positions, config, scale=True) for _ in range(config.n_layer) ] ) self.register_buffer("position_ids", torch.arange(config.n_positions)) # 初始化权重并应用到编解码阶段 self.post_init() #XAttn表示交叉注意力(Cross-Attention),对输入的提示序列和历史交互序列进行编码,并通过交叉注意力机制将提示序列与历史交互序列进行关联。这样,模型可以在生成下一步动作时考虑到提示信息和先前的交互历史。 class XAttnGPT(OpenAIGPTPreTrainedModel): def __init__( self, embd_dim: int = 768, *, n_positions: int = 512, n_layer: int = 12, n_head: int = 12, dropout: float = 0.1, xattn_n_head: int = 8, xattn_ff_expanding: int = 4, xattn_detach_qk: bool = False, xattn_n_positions: int, use_geglu: bool = False, ): #HFGPT(历史注意力)在生成下一步动作时主要关注历史交互序列,而不是提示序列。使用GPT对历史交互序列进行编码,并通过自注意力机制(Self-Attention)捕捉序列中的上下文信息,以生成下一步动作。 class HFGPT(nn.Module) #略 #3.解码:Action Embedding(动作嵌入):将机器人的动作编码为嵌入向量,包含ActionEmbedding, ContinuousActionEmbedding两部分。ActionEmbedding将机器人的离散动作符号(如"pick and place"或"wipe")转换为嵌入向量(如使用整数编码),以便模型能够对其进行处理和预测。这种嵌入表示可以捕捉到不同动作之间的语义关系和相似性。 class ActionEmbedding(nn.Module): def __init__(self, output_dim: int, *, embed_dict: dict[str, nn.Module]): super().__init__() self._embed_dict = nn.ModuleDict(embed_dict) embed_dict_output_dim = sum( embed_dict[k].output_dim for k in sorted(embed_dict.keys()) ) self._post_layer = ( nn.Identity() if output_dim == embed_dict_output_dim else nn.Linear(embed_dict_output_dim, output_dim) ) self._output_dim = output_dim self._input_fields_checked = False #ContinuousActionEmbedding:将机器人的连续动作(通常由一组连续的数值表示,如机器人臂的位置和姿态)转换为嵌入向量,可以捕捉到不同连续动作之间的关系和变化。 class ContinuousActionEmbedding(nn.Module): #略 #Action Decoder(动作解码器):使用解码器部分生成机器人的动作序列。创建一个包含多个解码器的模块字典用于将神经网络输出转换为对应的动作。参数action_dims表示每个动作的维度,可以是一个整数(用CategoricalNet解码)或一个整数列表(用MultiCategoricalNet解码)。 self._decoders = nn.ModuleDict() for k, v in action_dims.items(): if isinstance(v, int): self._decoders[k] = CategoricalNet( #略 ) elif isinstance(v, list): self._decoders[k] = MultiCategoricalNet( input_dim, action_dims=v, hidden_dim=hidden_dim, hidden_depth=hidden_depth, activation=activation, norm_type=norm_type, last_layer_gain=last_layer_gain, ) else: raise ValueError(f"Invalid action_dims value: {v}") class MultiCategoricalNet(nn.Module): def __init__( self, input_dim: int, #接收输入维度 *, action_dims: list[int], #动作维度列表 hidden_dim: int, #隐藏层维度 hidden_depth: int, activation: str | Callable = "relu", norm_type: Literal["batchnorm", "layernorm"] | None = None, last_layer_gain: float | None = 0.01, #最后一层初始化增益 ): super().__init__() #调用父类的初始化函数 self.mlps = nn.ModuleList() #创建一个空的nn.ModuleList存储多个MLP感知网络 for action in action_dims: #遍历动作维度列表 net = _build_mlp_distribution_net( #构建MLP分布网络 #略 ) self.mlps.append(net) self.head = MultiCategoricalHead(action_dims)#创建一个MultiCategoricalHead对象传入动作维度列表
复制
#1.编码:将视觉提示中的物体信息和多个视角的RGB图像编码为嵌入向量表示,以供后续的序列建模和决策生成步骤使用,包含ObjEncoder,GatoMultiViewRGBEncoder, MultiViewRGBPerceiverEncoder, MultiViewRGBEncoder四部分,实际使用的是vit模型。 #ObjEncoder部分,将输入的物体图像或特征提取为物体的表示 self.cropped_img_encoder = ViTEncoder( output_dim=vit_output_dim, resolution=vit_resolution, patch_size=vit_patch_size, width=vit_width, layers=vit_layers, heads=vit_heads, ) #GatoMultiViewRGBEncoder:多视角RGB编码器,用于对多个视角的RGB图像进行编码转换为嵌入向量表示。 #MultiViewRGBPerceiverEncoder:多视角RGB Perceiver编码器。Perceiver是一种结合了注意力机制和卷积操作的神经网络结构,用于处理结构化输入和输出。 #MultiViewRGBEncoder:一个多视角RGB编码器,用于对多个视角的RGB图像进行编码。 #2.(基于GPT的序列建模方法)序列建模,包含引入OpenAIGPTPreTrainedModel(gpt预训练模型)和XAttnGPT、HFGPT三部分。学习输入序列的语义表示和序列之间的关联,从而生成合理的机器人动作序列。 from transformers.models.openai.modeling_openai import ( OpenAIGPTPreTrainedModel, OpenAIGPTConfig, ) #gpt def __init__(self, config): super().__init__(config) self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd) self.positions_embed = nn.Embedding(config.n_positions, config.n_embd) self.drop = nn.Dropout(config.embd_pdrop) self.h = nn.ModuleList( [ Block(config.n_positions, config, scale=True) for _ in range(config.n_layer) ] ) self.register_buffer("position_ids", torch.arange(config.n_positions)) # 初始化权重并应用到编解码阶段 self.post_init() #XAttn表示交叉注意力(Cross-Attention),对输入的提示序列和历史交互序列进行编码,并通过交叉注意力机制将提示序列与历史交互序列进行关联。这样,模型可以在生成下一步动作时考虑到提示信息和先前的交互历史。 class XAttnGPT(OpenAIGPTPreTrainedModel): def __init__( self, embd_dim: int = 768, *, n_positions: int = 512, n_layer: int = 12, n_head: int = 12, dropout: float = 0.1, xattn_n_head: int = 8, xattn_ff_expanding: int = 4, xattn_detach_qk: bool = False, xattn_n_positions: int, use_geglu: bool = False, ): #HFGPT(历史注意力)在生成下一步动作时主要关注历史交互序列,而不是提示序列。使用GPT对历史交互序列进行编码,并通过自注意力机制(Self-Attention)捕捉序列中的上下文信息,以生成下一步动作。 class HFGPT(nn.Module) #略 #3.解码:Action Embedding(动作嵌入):将机器人的动作编码为嵌入向量,包含ActionEmbedding, ContinuousActionEmbedding两部分。ActionEmbedding将机器人的离散动作符号(如"pick and place"或"wipe")转换为嵌入向量(如使用整数编码),以便模型能够对其进行处理和预测。这种嵌入表示可以捕捉到不同动作之间的语义关系和相似性。 class ActionEmbedding(nn.Module): def __init__(self, output_dim: int, *, embed_dict: dict[str, nn.Module]): super().__init__() self._embed_dict = nn.ModuleDict(embed_dict) embed_dict_output_dim = sum( embed_dict[k].output_dim for k in sorted(embed_dict.keys()) ) self._post_layer = ( nn.Identity() if output_dim == embed_dict_output_dim else nn.Linear(embed_dict_output_dim, output_dim) ) self._output_dim = output_dim self._input_fields_checked = False #ContinuousActionEmbedding:将机器人的连续动作(通常由一组连续的数值表示,如机器人臂的位置和姿态)转换为嵌入向量,可以捕捉到不同连续动作之间的关系和变化。 class ContinuousActionEmbedding(nn.Module): #略 #Action Decoder(动作解码器):使用解码器部分生成机器人的动作序列。创建一个包含多个解码器的模块字典用于将神经网络输出转换为对应的动作。参数action_dims表示每个动作的维度,可以是一个整数(用CategoricalNet解码)或一个整数列表(用MultiCategoricalNet解码)。 self._decoders = nn.ModuleDict() for k, v in action_dims.items(): if isinstance(v, int): self._decoders[k] = CategoricalNet( #略 ) elif isinstance(v, list): self._decoders[k] = MultiCategoricalNet( input_dim, action_dims=v, hidden_dim=hidden_dim, hidden_depth=hidden_depth, activation=activation, norm_type=norm_type, last_layer_gain=last_layer_gain, ) else: raise ValueError(f"Invalid action_dims value: {v}") class MultiCategoricalNet(nn.Module): def __init__( self, input_dim: int, #接收输入维度 *, action_dims: list[int], #动作维度列表 hidden_dim: int, #隐藏层维度 hidden_depth: int, activation: str | Callable = "relu", norm_type: Literal["batchnorm", "layernorm"] | None = None, last_layer_gain: float | None = 0.01, #最后一层初始化增益 ): super().__init__() #调用父类的初始化函数 self.mlps = nn.ModuleList() #创建一个空的nn.ModuleList存储多个MLP感知网络 for action in action_dims: #遍历动作维度列表 net = _build_mlp_distribution_net( #构建MLP分布网络 #略 ) self.mlps.append(net) self.head = MultiCategoricalHead(action_dims)#创建一个MultiCategoricalHead对象传入动作维度列表
#1.编码:将视觉提示中的物体信息和多个视角的RGB图像编码为嵌入向量表示,以供后续的序列建模和决策生成步骤使用,包含ObjEncoder,GatoMultiViewRGBEncoder, MultiViewRGBPerceiverEncoder, MultiViewRGBEncoder四部分,实际使用的是vit模型。 #ObjEncoder部分,将输入的物体图像或特征提取为物体的表示 self.cropped_img_encoder = ViTEncoder( output_dim=vit_output_dim, resolution=vit_resolution, patch_size=vit_patch_size, width=vit_width, layers=vit_layers, heads=vit_heads, ) #GatoMultiViewRGBEncoder:多视角RGB编码器,用于对多个视角的RGB图像进行编码转换为嵌入向量表示。 #MultiViewRGBPerceiverEncoder:多视角RGB Perceiver编码器。Perceiver是一种结合了注意力机制和卷积操作的神经网络结构,用于处理结构化输入和输出。 #MultiViewRGBEncoder:一个多视角RGB编码器,用于对多个视角的RGB图像进行编码。 #2.(基于GPT的序列建模方法)序列建模,包含引入OpenAIGPTPreTrainedModel(gpt预训练模型)和XAttnGPT、HFGPT三部分。学习输入序列的语义表示和序列之间的关联,从而生成合理的机器人动作序列。 from transformers.models.openai.modeling_openai import ( OpenAIGPTPreTrainedModel, OpenAIGPTConfig, ) #gpt def __init__(self, config): super().__init__(config) self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd) self.positions_embed = nn.Embedding(config.n_positions, config.n_embd) self.drop = nn.Dropout(config.embd_pdrop) self.h = nn.ModuleList( [ Block(config.n_positions, config, scale=True) for _ in range(config.n_layer) ] ) self.register_buffer("position_ids", torch.arange(config.n_positions)) # 初始化权重并应用到编解码阶段 self.post_init() #XAttn表示交叉注意力(Cross-Attention),对输入的提示序列和历史交互序列进行编码,并通过交叉注意力机制将提示序列与历史交互序列进行关联。这样,模型可以在生成下一步动作时考虑到提示信息和先前的交互历史。 class XAttnGPT(OpenAIGPTPreTrainedModel): def __init__( self, embd_dim: int = 768, *, n_positions: int = 512, n_layer: int = 12, n_head: int = 12, dropout: float = 0.1, xattn_n_head: int = 8, xattn_ff_expanding: int = 4, xattn_detach_qk: bool = False, xattn_n_positions: int, use_geglu: bool = False, ): #HFGPT(历史注意力)在生成下一步动作时主要关注历史交互序列,而不是提示序列。使用GPT对历史交互序列进行编码,并通过自注意力机制(Self-Attention)捕捉序列中的上下文信息,以生成下一步动作。 class HFGPT(nn.Module) #略 #3.解码:Action Embedding(动作嵌入):将机器人的动作编码为嵌入向量,包含ActionEmbedding, ContinuousActionEmbedding两部分。ActionEmbedding将机器人的离散动作符号(如"pick and place"或"wipe")转换为嵌入向量(如使用整数编码),以便模型能够对其进行处理和预测。这种嵌入表示可以捕捉到不同动作之间的语义关系和相似性。 class ActionEmbedding(nn.Module): def __init__(self, output_dim: int, *, embed_dict: dict[str, nn.Module]): super().__init__() self._embed_dict = nn.ModuleDict(embed_dict) embed_dict_output_dim = sum( embed_dict[k].output_dim for k in sorted(embed_dict.keys()) ) self._post_layer = ( nn.Identity() if output_dim == embed_dict_output_dim else nn.Linear(embed_dict_output_dim, output_dim) ) self._output_dim = output_dim self._input_fields_checked = False #ContinuousActionEmbedding:将机器人的连续动作(通常由一组连续的数值表示,如机器人臂的位置和姿态)转换为嵌入向量,可以捕捉到不同连续动作之间的关系和变化。 class ContinuousActionEmbedding(nn.Module): #略 #Action Decoder(动作解码器):使用解码器部分生成机器人的动作序列。创建一个包含多个解码器的模块字典用于将神经网络输出转换为对应的动作。参数action_dims表示每个动作的维度,可以是一个整数(用CategoricalNet解码)或一个整数列表(用MultiCategoricalNet解码)。 self._decoders = nn.ModuleDict() for k, v in action_dims.items(): if isinstance(v, int): self._decoders[k] = CategoricalNet( #略 ) elif isinstance(v, list): self._decoders[k] = MultiCategoricalNet( input_dim, action_dims=v, hidden_dim=hidden_dim, hidden_depth=hidden_depth, activation=activation, norm_type=norm_type, last_layer_gain=last_layer_gain, ) else: raise ValueError(f"Invalid action_dims value: {v}") class MultiCategoricalNet(nn.Module): def __init__( self, input_dim: int, #接收输入维度 *, action_dims: list[int], #动作维度列表 hidden_dim: int, #隐藏层维度 hidden_depth: int, activation: str | Callable = "relu", norm_type: Literal["batchnorm", "layernorm"] | None = None, last_layer_gain: float | None = 0.01, #最后一层初始化增益 ): super().__init__() #调用父类的初始化函数 self.mlps = nn.ModuleList() #创建一个空的nn.ModuleList存储多个MLP感知网络 for action in action_dims: #遍历动作维度列表 net = _build_mlp_distribution_net( #构建MLP分布网络 #略 ) self.mlps.append(net) self.head = MultiCategoricalHead(action_dims)#创建一个MultiCategoricalHead对象传入动作维度列表
#1.编码:将视觉提示中的物体信息和多个视角的RGB图像编码为嵌入向量表示,以供后续的序列建模和决策生成步骤使用,包含ObjEncoder,GatoMultiViewRGBEncoder, MultiViewRGBPerceiverEncoder, MultiViewRGBEncoder四部分,实际使用的是vit模型。 #ObjEncoder部分,将输入的物体图像或特征提取为物体的表示 self.cropped_img_encoder = ViTEncoder( output_dim=vit_output_dim, resolution=vit_resolution, patch_size=vit_patch_size, width=vit_width, layers=vit_layers, heads=vit_heads, ) #GatoMultiViewRGBEncoder:多视角RGB编码器,用于对多个视角的RGB图像进行编码转换为嵌入向量表示。 #MultiViewRGBPerceiverEncoder:多视角RGB Perceiver编码器。Perceiver是一种结合了注意力机制和卷积操作的神经网络结构,用于处理结构化输入和输出。 #MultiViewRGBEncoder:一个多视角RGB编码器,用于对多个视角的RGB图像进行编码。 #2.(基于GPT的序列建模方法)序列建模,包含引入OpenAIGPTPreTrainedModel(gpt预训练模型)和XAttnGPT、HFGPT三部分。学习输入序列的语义表示和序列之间的关联,从而生成合理的机器人动作序列。 from transformers.models.openai.modeling_openai import ( OpenAIGPTPreTrainedModel, OpenAIGPTConfig, ) #gpt def __init__(self, config): super().__init__(config) self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd) self.positions_embed = nn.Embedding(config.n_positions, config.n_embd) self.drop = nn.Dropout(config.embd_pdrop) self.h = nn.ModuleList( [ Block(config.n_positions, config, scale=True) for _ in range(config.n_layer) ] ) self.register_buffer("position_ids", torch.arange(config.n_positions)) # 初始化权重并应用到编解码阶段 self.post_init() #XAttn表示交叉注意力(Cross-Attention),对输入的提示序列和历史交互序列进行编码,并通过交叉注意力机制将提示序列与历史交互序列进行关联。这样,模型可以在生成下一步动作时考虑到提示信息和先前的交互历史。 class XAttnGPT(OpenAIGPTPreTrainedModel): def __init__( self, embd_dim: int = 768, *, n_positions: int = 512, n_layer: int = 12, n_head: int = 12, dropout: float = 0.1, xattn_n_head: int = 8, xattn_ff_expanding: int = 4, xattn_detach_qk: bool = False, xattn_n_positions: int, use_geglu: bool = False, ): #HFGPT(历史注意力)在生成下一步动作时主要关注历史交互序列,而不是提示序列。使用GPT对历史交互序列进行编码,并通过自注意力机制(Self-Attention)捕捉序列中的上下文信息,以生成下一步动作。 class HFGPT(nn.Module) #略 #3.解码:Action Embedding(动作嵌入):将机器人的动作编码为嵌入向量,包含ActionEmbedding, ContinuousActionEmbedding两部分。ActionEmbedding将机器人的离散动作符号(如"pick and place"或"wipe")转换为嵌入向量(如使用整数编码),以便模型能够对其进行处理和预测。这种嵌入表示可以捕捉到不同动作之间的语义关系和相似性。 class ActionEmbedding(nn.Module): def __init__(self, output_dim: int, *, embed_dict: dict[str, nn.Module]): super().__init__() self._embed_dict = nn.ModuleDict(embed_dict) embed_dict_output_dim = sum( embed_dict[k].output_dim for k in sorted(embed_dict.keys()) ) self._post_layer = ( nn.Identity() if output_dim == embed_dict_output_dim else nn.Linear(embed_dict_output_dim, output_dim) ) self._output_dim = output_dim self._input_fields_checked = False #ContinuousActionEmbedding:将机器人的连续动作(通常由一组连续的数值表示,如机器人臂的位置和姿态)转换为嵌入向量,可以捕捉到不同连续动作之间的关系和变化。 class ContinuousActionEmbedding(nn.Module): #略 #Action Decoder(动作解码器):使用解码器部分生成机器人的动作序列。创建一个包含多个解码器的模块字典用于将神经网络输出转换为对应的动作。参数action_dims表示每个动作的维度,可以是一个整数(用CategoricalNet解码)或一个整数列表(用MultiCategoricalNet解码)。 self._decoders = nn.ModuleDict() for k, v in action_dims.items(): if isinstance(v, int): self._decoders[k] = CategoricalNet( #略 ) elif isinstance(v, list): self._decoders[k] = MultiCategoricalNet( input_dim, action_dims=v, hidden_dim=hidden_dim, hidden_depth=hidden_depth, activation=activation, norm_type=norm_type, last_layer_gain=last_layer_gain, ) else: raise ValueError(f"Invalid action_dims value: {v}") class MultiCategoricalNet(nn.Module): def __init__( self, input_dim: int, #接收输入维度 *, action_dims: list[int], #动作维度列表 hidden_dim: int, #隐藏层维度 hidden_depth: int, activation: str | Callable = "relu", norm_type: Literal["batchnorm", "layernorm"] | None = None, last_layer_gain: float | None = 0.01, #最后一层初始化增益 ): super().__init__() #调用父类的初始化函数 self.mlps = nn.ModuleList() #创建一个空的nn.ModuleList存储多个MLP感知网络 for action in action_dims: #遍历动作维度列表 net = _build_mlp_distribution_net( #构建MLP分布网络 #略 ) self.mlps.append(net) self.head = MultiCategoricalHead(action_dims)#创建一个MultiCategoricalHead对象传入动作维度列表
#1.编码:将视觉提示中的物体信息和多个视角的RGB图像编码为嵌入向量表示,以供后续的序列建模和决策生成步骤使用,包含ObjEncoder,GatoMultiViewRGBEncoder, MultiViewRGBPerceiverEncoder, MultiViewRGBEncoder四部分,实际使用的是vit模型。 #ObjEncoder部分,将输入的物体图像或特征提取为物体的表示 self.cropped_img_encoder = ViTEncoder( output_dim=vit_output_dim, resolution=vit_resolution, patch_size=vit_patch_size, width=vit_width, layers=vit_layers, heads=vit_heads, ) #GatoMultiViewRGBEncoder:多视角RGB编码器,用于对多个视角的RGB图像进行编码转换为嵌入向量表示。 #MultiViewRGBPerceiverEncoder:多视角RGB Perceiver编码器。Perceiver是一种结合了注意力机制和卷积操作的神经网络结构,用于处理结构化输入和输出。 #MultiViewRGBEncoder:一个多视角RGB编码器,用于对多个视角的RGB图像进行编码。 #2.(基于GPT的序列建模方法)序列建模,包含引入OpenAIGPTPreTrainedModel(gpt预训练模型)和XAttnGPT、HFGPT三部分。学习输入序列的语义表示和序列之间的关联,从而生成合理的机器人动作序列。 from transformers.models.openai.modeling_openai import ( OpenAIGPTPreTrainedModel, OpenAIGPTConfig, ) #gpt def __init__(self, config): super().__init__(config) self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd) self.positions_embed = nn.Embedding(config.n_positions, config.n_embd) self.drop = nn.Dropout(config.embd_pdrop) self.h = nn.ModuleList( [ Block(config.n_positions, config, scale=True) for _ in range(config.n_layer) ] ) self.register_buffer("position_ids", torch.arange(config.n_positions)) # 初始化权重并应用到编解码阶段 self.post_init() #XAttn表示交叉注意力(Cross-Attention),对输入的提示序列和历史交互序列进行编码,并通过交叉注意力机制将提示序列与历史交互序列进行关联。这样,模型可以在生成下一步动作时考虑到提示信息和先前的交互历史。 class XAttnGPT(OpenAIGPTPreTrainedModel): def __init__( self, embd_dim: int = 768, *, n_positions: int = 512, n_layer: int = 12, n_head: int = 12, dropout: float = 0.1, xattn_n_head: int = 8, xattn_ff_expanding: int = 4, xattn_detach_qk: bool = False, xattn_n_positions: int, use_geglu: bool = False, ): #HFGPT(历史注意力)在生成下一步动作时主要关注历史交互序列,而不是提示序列。使用GPT对历史交互序列进行编码,并通过自注意力机制(Self-Attention)捕捉序列中的上下文信息,以生成下一步动作。 class HFGPT(nn.Module) #略 #3.解码:Action Embedding(动作嵌入):将机器人的动作编码为嵌入向量,包含ActionEmbedding, ContinuousActionEmbedding两部分。ActionEmbedding将机器人的离散动作符号(如"pick and place"或"wipe")转换为嵌入向量(如使用整数编码),以便模型能够对其进行处理和预测。这种嵌入表示可以捕捉到不同动作之间的语义关系和相似性。 class ActionEmbedding(nn.Module): def __init__(self, output_dim: int, *, embed_dict: dict[str, nn.Module]): super().__init__() self._embed_dict = nn.ModuleDict(embed_dict) embed_dict_output_dim = sum( embed_dict[k].output_dim for k in sorted(embed_dict.keys()) ) self._post_layer = ( nn.Identity() if output_dim == embed_dict_output_dim else nn.Linear(embed_dict_output_dim, output_dim) ) self._output_dim = output_dim self._input_fields_checked = False #ContinuousActionEmbedding:将机器人的连续动作(通常由一组连续的数值表示,如机器人臂的位置和姿态)转换为嵌入向量,可以捕捉到不同连续动作之间的关系和变化。 class ContinuousActionEmbedding(nn.Module): #略 #Action Decoder(动作解码器):使用解码器部分生成机器人的动作序列。创建一个包含多个解码器的模块字典用于将神经网络输出转换为对应的动作。参数action_dims表示每个动作的维度,可以是一个整数(用CategoricalNet解码)或一个整数列表(用MultiCategoricalNet解码)。 self._decoders = nn.ModuleDict() for k, v in action_dims.items(): if isinstance(v, int): self._decoders[k] = CategoricalNet( #略 ) elif isinstance(v, list): self._decoders[k] = MultiCategoricalNet( input_dim, action_dims=v, hidden_dim=hidden_dim, hidden_depth=hidden_depth, activation=activation, norm_type=norm_type, last_layer_gain=last_layer_gain, ) else: raise ValueError(f"Invalid action_dims value: {v}") class MultiCategoricalNet(nn.Module): def __init__( self, input_dim: int, #接收输入维度 *, action_dims: list[int], #动作维度列表 hidden_dim: int, #隐藏层维度 hidden_depth: int, activation: str | Callable = "relu", norm_type: Literal["batchnorm", "layernorm"] | None = None, last_layer_gain: float | None = 0.01, #最后一层初始化增益 ): super().__init__() #调用父类的初始化函数 self.mlps = nn.ModuleList() #创建一个空的nn.ModuleList存储多个MLP感知网络 for action in action_dims: #遍历动作维度列表 net = _build_mlp_distribution_net( #构建MLP分布网络 #略 ) self.mlps.append(net) self.head = MultiCategoricalHead(action_dims)#创建一个MultiCategoricalHead对象传入动作维度列表
#1.编码:将视觉提示中的物体信息和多个视角的RGB图像编码为嵌入向量表示,以供后续的序列建模和决策生成步骤使用,包含ObjEncoder,GatoMultiViewRGBEncoder, MultiViewRGBPerceiverEncoder, MultiViewRGBEncoder四部分,实际使用的是vit模型。 #ObjEncoder部分,将输入的物体图像或特征提取为物体的表示 self.cropped_img_encoder = ViTEncoder( output_dim=vit_output_dim, resolution=vit_resolution, patch_size=vit_patch_size, width=vit_width, layers=vit_layers, heads=vit_heads, ) #GatoMultiViewRGBEncoder:多视角RGB编码器,用于对多个视角的RGB图像进行编码转换为嵌入向量表示。 #MultiViewRGBPerceiverEncoder:多视角RGB Perceiver编码器。Perceiver是一种结合了注意力机制和卷积操作的神经网络结构,用于处理结构化输入和输出。 #MultiViewRGBEncoder:一个多视角RGB编码器,用于对多个视角的RGB图像进行编码。 #2.(基于GPT的序列建模方法)序列建模,包含引入OpenAIGPTPreTrainedModel(gpt预训练模型)和XAttnGPT、HFGPT三部分。学习输入序列的语义表示和序列之间的关联,从而生成合理的机器人动作序列。 from transformers.models.openai.modeling_openai import ( OpenAIGPTPreTrainedModel, OpenAIGPTConfig, ) #gpt def __init__(self, config): super().__init__(config) self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd) self.positions_embed = nn.Embedding(config.n_positions, config.n_embd) self.drop = nn.Dropout(config.embd_pdrop) self.h = nn.ModuleList( [ Block(config.n_positions, config, scale=True) for _ in range(config.n_layer) ] ) self.register_buffer("position_ids", torch.arange(config.n_positions)) # 初始化权重并应用到编解码阶段 self.post_init() #XAttn表示交叉注意力(Cross-Attention),对输入的提示序列和历史交互序列进行编码,并通过交叉注意力机制将提示序列与历史交互序列进行关联。这样,模型可以在生成下一步动作时考虑到提示信息和先前的交互历史。 class XAttnGPT(OpenAIGPTPreTrainedModel): def __init__( self, embd_dim: int = 768, *, n_positions: int = 512, n_layer: int = 12, n_head: int = 12, dropout: float = 0.1, xattn_n_head: int = 8, xattn_ff_expanding: int = 4, xattn_detach_qk: bool = False, xattn_n_positions: int, use_geglu: bool = False, ): #HFGPT(历史注意力)在生成下一步动作时主要关注历史交互序列,而不是提示序列。使用GPT对历史交互序列进行编码,并通过自注意力机制(Self-Attention)捕捉序列中的上下文信息,以生成下一步动作。 class HFGPT(nn.Module) #略 #3.解码:Action Embedding(动作嵌入):将机器人的动作编码为嵌入向量,包含ActionEmbedding, ContinuousActionEmbedding两部分。ActionEmbedding将机器人的离散动作符号(如"pick and place"或"wipe")转换为嵌入向量(如使用整数编码),以便模型能够对其进行处理和预测。这种嵌入表示可以捕捉到不同动作之间的语义关系和相似性。 class ActionEmbedding(nn.Module): def __init__(self, output_dim: int, *, embed_dict: dict[str, nn.Module]): super().__init__() self._embed_dict = nn.ModuleDict(embed_dict) embed_dict_output_dim = sum( embed_dict[k].output_dim for k in sorted(embed_dict.keys()) ) self._post_layer = ( nn.Identity() if output_dim == embed_dict_output_dim else nn.Linear(embed_dict_output_dim, output_dim) ) self._output_dim = output_dim self._input_fields_checked = False #ContinuousActionEmbedding:将机器人的连续动作(通常由一组连续的数值表示,如机器人臂的位置和姿态)转换为嵌入向量,可以捕捉到不同连续动作之间的关系和变化。 class ContinuousActionEmbedding(nn.Module): #略 #Action Decoder(动作解码器):使用解码器部分生成机器人的动作序列。创建一个包含多个解码器的模块字典用于将神经网络输出转换为对应的动作。参数action_dims表示每个动作的维度,可以是一个整数(用CategoricalNet解码)或一个整数列表(用MultiCategoricalNet解码)。 self._decoders = nn.ModuleDict() for k, v in action_dims.items(): if isinstance(v, int): self._decoders[k] = CategoricalNet( #略 ) elif isinstance(v, list): self._decoders[k] = MultiCategoricalNet( input_dim, action_dims=v, hidden_dim=hidden_dim, hidden_depth=hidden_depth, activation=activation, norm_type=norm_type, last_layer_gain=last_layer_gain, ) else: raise ValueError(f"Invalid action_dims value: {v}") class MultiCategoricalNet(nn.Module): def __init__( self, input_dim: int, #接收输入维度 *, action_dims: list[int], #动作维度列表 hidden_dim: int, #隐藏层维度 hidden_depth: int, activation: str | Callable = "relu", norm_type: Literal["batchnorm", "layernorm"] | None = None, last_layer_gain: float | None = 0.01, #最后一层初始化增益 ): super().__init__() #调用父类的初始化函数 self.mlps = nn.ModuleList() #创建一个空的nn.ModuleList存储多个MLP感知网络 for action in action_dims: #遍历动作维度列表 net = _build_mlp_distribution_net( #构建MLP分布网络 #略 ) self.mlps.append(net) self.head = MultiCategoricalHead(action_dims)#创建一个MultiCategoricalHead对象传入动作维度列表
复制
#1.编码:将视觉提示中的物体信息和多个视角的RGB图像编码为嵌入向量表示,以供后续的序列建模和决策生成步骤使用,包含ObjEncoder,GatoMultiViewRGBEncoder, MultiViewRGBPerceiverEncoder, MultiViewRGBEncoder四部分,实际使用的是vit模型。 #ObjEncoder部分,将输入的物体图像或特征提取为物体的表示 self.cropped_img_encoder = ViTEncoder( output_dim=vit_output_dim, resolution=vit_resolution, patch_size=vit_patch_size, width=vit_width, layers=vit_layers, heads=vit_heads, ) #GatoMultiViewRGBEncoder:多视角RGB编码器,用于对多个视角的RGB图像进行编码转换为嵌入向量表示。 #MultiViewRGBPerceiverEncoder:多视角RGB Perceiver编码器。Perceiver是一种结合了注意力机制和卷积操作的神经网络结构,用于处理结构化输入和输出。 #MultiViewRGBEncoder:一个多视角RGB编码器,用于对多个视角的RGB图像进行编码。 #2.(基于GPT的序列建模方法)序列建模,包含引入OpenAIGPTPreTrainedModel(gpt预训练模型)和XAttnGPT、HFGPT三部分。学习输入序列的语义表示和序列之间的关联,从而生成合理的机器人动作序列。 from transformers.models.openai.modeling_openai import ( OpenAIGPTPreTrainedModel, OpenAIGPTConfig, ) #gpt def __init__(self, config): super().__init__(config) self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd) self.positions_embed = nn.Embedding(config.n_positions, config.n_embd) self.drop = nn.Dropout(config.embd_pdrop) self.h = nn.ModuleList( [ Block(config.n_positions, config, scale=True) for _ in range(config.n_layer) ] ) self.register_buffer("position_ids", torch.arange(config.n_positions)) # 初始化权重并应用到编解码阶段 self.post_init() #XAttn表示交叉注意力(Cross-Attention),对输入的提示序列和历史交互序列进行编码,并通过交叉注意力机制将提示序列与历史交互序列进行关联。这样,模型可以在生成下一步动作时考虑到提示信息和先前的交互历史。 class XAttnGPT(OpenAIGPTPreTrainedModel): def __init__( self, embd_dim: int = 768, *, n_positions: int = 512, n_layer: int = 12, n_head: int = 12, dropout: float = 0.1, xattn_n_head: int = 8, xattn_ff_expanding: int = 4, xattn_detach_qk: bool = False, xattn_n_positions: int, use_geglu: bool = False, ): #HFGPT(历史注意力)在生成下一步动作时主要关注历史交互序列,而不是提示序列。使用GPT对历史交互序列进行编码,并通过自注意力机制(Self-Attention)捕捉序列中的上下文信息,以生成下一步动作。 class HFGPT(nn.Module) #略 #3.解码:Action Embedding(动作嵌入):将机器人的动作编码为嵌入向量,包含ActionEmbedding, ContinuousActionEmbedding两部分。ActionEmbedding将机器人的离散动作符号(如"pick and place"或"wipe")转换为嵌入向量(如使用整数编码),以便模型能够对其进行处理和预测。这种嵌入表示可以捕捉到不同动作之间的语义关系和相似性。 class ActionEmbedding(nn.Module): def __init__(self, output_dim: int, *, embed_dict: dict[str, nn.Module]): super().__init__() self._embed_dict = nn.ModuleDict(embed_dict) embed_dict_output_dim = sum( embed_dict[k].output_dim for k in sorted(embed_dict.keys()) ) self._post_layer = ( nn.Identity() if output_dim == embed_dict_output_dim else nn.Linear(embed_dict_output_dim, output_dim) ) self._output_dim = output_dim self._input_fields_checked = False #ContinuousActionEmbedding:将机器人的连续动作(通常由一组连续的数值表示,如机器人臂的位置和姿态)转换为嵌入向量,可以捕捉到不同连续动作之间的关系和变化。 class ContinuousActionEmbedding(nn.Module): #略 #Action Decoder(动作解码器):使用解码器部分生成机器人的动作序列。创建一个包含多个解码器的模块字典用于将神经网络输出转换为对应的动作。参数action_dims表示每个动作的维度,可以是一个整数(用CategoricalNet解码)或一个整数列表(用MultiCategoricalNet解码)。 self._decoders = nn.ModuleDict() for k, v in action_dims.items(): if isinstance(v, int): self._decoders[k] = CategoricalNet( #略 ) elif isinstance(v, list): self._decoders[k] = MultiCategoricalNet( input_dim, action_dims=v, hidden_dim=hidden_dim, hidden_depth=hidden_depth, activation=activation, norm_type=norm_type, last_layer_gain=last_layer_gain, ) else: raise ValueError(f"Invalid action_dims value: {v}") class MultiCategoricalNet(nn.Module): def __init__( self, input_dim: int, #接收输入维度 *, action_dims: list[int], #动作维度列表 hidden_dim: int, #隐藏层维度 hidden_depth: int, activation: str | Callable = "relu", norm_type: Literal["batchnorm", "layernorm"] | None = None, last_layer_gain: float | None = 0.01, #最后一层初始化增益 ): super().__init__() #调用父类的初始化函数 self.mlps = nn.ModuleList() #创建一个空的nn.ModuleList存储多个MLP感知网络 for action in action_dims: #遍历动作维度列表 net = _build_mlp_distribution_net( #构建MLP分布网络 #略 ) self.mlps.append(net) self.head = MultiCategoricalHead(action_dims)#创建一个MultiCategoricalHead对象传入动作维度列表
3.通过1、2完成多模态提示多任务的学习(端到端的监督学习),(模型可以从人类专家轨迹数据中学习执行各种任务所需的动作序列)可执行多个不同的机器人操作任务。零样本泛化(通过多模态提示的序列建模和语义理解):无特定任务训练的情况下执行新任务。
Tips:不直接控制机器人,只是仿真环境利用policy进行仿真控制。据说代码坑比较多,不过可以作为未开源palm-e的初始编码版本,https://vimalabs.github.io/


")


评论(0)
您还未登录,请登录后发表或查看评论