

Skipgram
我们不仅要考虑目标单词的前两个单词,还要考虑其后两个单词
如果这么做,我们实际上构建并训练的模型就如下所示:
上述的这种架构被称为连续词袋(CBOW),在一篇关于word2vec的论文中有阐述。
还有另一种架构,它不根据前后文(前后单词)来猜测目标单词,而是推测当前单词可能的前后单词。我们设想一下滑动窗在训练数据时如下图所示: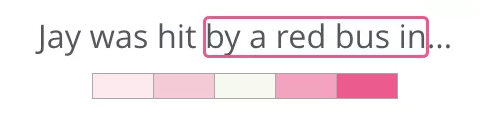
_绿框中的词语是输入词,粉框则是可能的输出结果_
这里粉框颜色深度呈现不同,是因为滑动窗给训练集产生了4个独立的样本: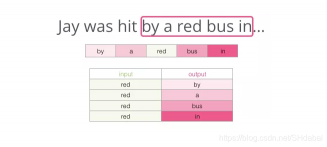
这种方式称为Skipgram架构。我们可以像下图这样将展示滑动窗的内容。
这样就为数据集提供了4个样本: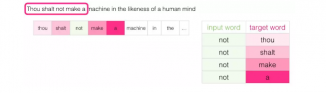
然后我们移动滑动窗到下一个位置: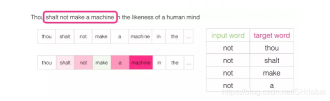
这样我们又产生了接下来4个样本: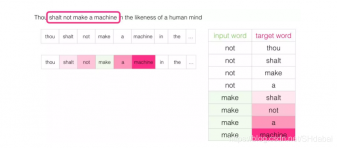
在移动几组位置之后,我们就能得到一批样本: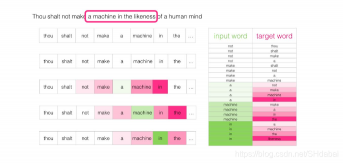
Revisiting the training process
现在我们已经从现有的文本中获得了Skipgram模型的训练数据集,接下来让我们看看如何使用它来训练一个能预测相邻词汇的自然语言模型。
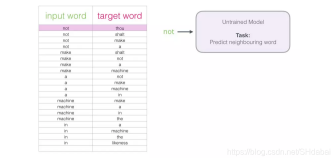
从数据集中的第一个样本开始。我们将特征输入到未经训练的模型,让它预测一个可能的相邻单词。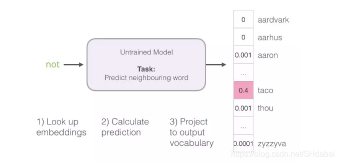
该模型会执行三个步骤并输入预测向量(对应于单词表中每个单词的概率)。因为模型未经训练,该阶段的预测肯定是错误的。但是没关系,我们知道应该猜出的是哪个单词——这个词就是我训练集数据中的输出标签: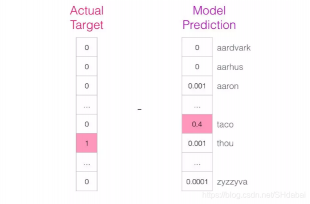
目标单词概率为1,其他所有单词概率为0,这样数值组成的向量就是“目标向量”。
模型的偏差有多少?将两个向量相减,就能得到偏差向量:
现在这一误差向量可以被用于更新模型了,所以在下一轮预测中,如果用not作为输入,我们更有可能得到thou作为输出了。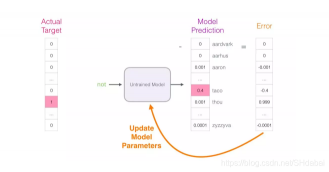
这其实就是训练的第一步了。我们接下来继续对数据集内下一份样本进行同样的操作,直到我们遍历所有的样本。这就是一轮(epoch)了。我们再多做几轮(epoch),得到训练过的模型,于是就可以从中提取嵌入矩阵来用于其他应用了。
以上确实有助于我们理解整个流程,但这依然不是word2vec真正训练的方法。我们错过了一些关键的想法。
Negative Sampling 负采样
回想一下这个神经语言模型计算预测值的三个步骤: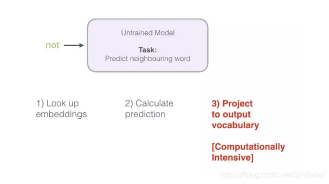
从计算的角度来看,第三步非常昂贵 - 尤其是当我们将需要在数据集中为每个训练样本都做一遍(很容易就多达数千万次)。我们需要寻找一些提高表现的方法。
一种方法是将目标分为两个步骤:
1.生成高质量的词嵌入(不要担心下一个单词预测)。
2.使用这些高质量的嵌入来训练语言模型(进行下一个单词预测)。
在本文中我们将专注于第1步(因为这篇文章专注于嵌入)。要使用高性能模型生成高质量嵌入,我们可以改变一下预测相邻单词这一任务:

将其切换到一个提取输入与输出单词的模型,并输出一个表明它们是否是邻居的分数(0表示“不是邻居”,1表示“邻居”)。
这个简单的变换将我们需要的模型从神经网络改为逻辑回归模型——因此它变得更简单,计算速度更快。
这个开关要求我们切换数据集的结构——标签值现在是一个值为0或1的新列。它们将全部为1,因为我们添加的所有单词都是邻居。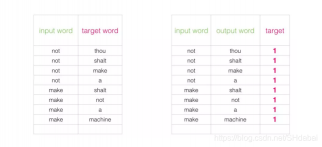
现在的计算速度可谓是神速啦——在几分钟内就能处理数百万个例子。但是我们还需要解决一个漏洞。如果所有的例子都是邻居(目标:1),我们这个”天才模型“可能会被训练得永远返回1——准确性是百分百了,但它什么东西都学不到,只会产生垃圾嵌入结果。
为了解决这个问题,我们需要在数据集中引入负样本 - 不是邻居的单词样本。我们的模型需要为这些样本返回0。模型必须努力解决这个挑战——而且依然必须保持高速。

_对于我们数据集中的每个样本,我们添加了负面示例。它们具有相同的输入字词,标签为0。_
但是我们作为输出词填写什么呢?我们从词汇表中随机抽取单词
这个想法的灵感来自噪声对比估计。我们将实际信号(相邻单词的正例)与噪声(随机选择的不是邻居的单词)进行对比。这导致了计算和统计效率的巨大折衷。
参考论文
基于负例采样的Skipgram(SGNS)
我们现在已经介绍了word2vec中的两个(一对)核心思想:负例采样,以及skipgram。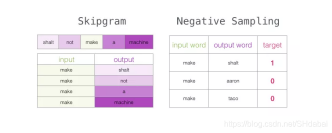
Word2vec训练流程
现在我们已经了解了skipgram和负例采样的两个中心思想,可以继续仔细研究实际的word2vec训练过程了。
在训练过程开始之前,我们预先处理我们正在训练模型的文本。在这一步中,我们确定一下词典的大小(我们称之为vocab_size,比如说10,000)以及哪些词被它包含在内。
在训练阶段的开始,我们创建两个矩阵——Embedding矩阵和Context矩阵。这两个矩阵在我们的词汇表中嵌入了每个单词(所以vocab_size是他们的维度之一)。第二个维度是我们希望每次嵌入的长度(embedding_size——300是一个常见值,但我们在前文也看过50的例子)。
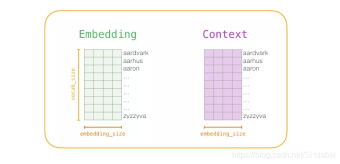
在训练过程开始时,我们用随机值初始化这些矩阵。然后我们开始训练过程。在每个训练步骤中,我们采取一个相邻的例子及其相关的非相邻例子。我们来看看我们的第一组: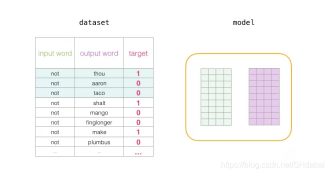
现在我们有四个单词:输入单词not和输出/上下文单词: thou(实际邻居词),aaron和taco(负面例子)。我们继续查找它们的嵌入——对于输入词,我们查看Embedding矩阵。对于上下文单词,我们查看Context矩阵(即使两个矩阵都在我们的词汇表中嵌入了每个单词)。
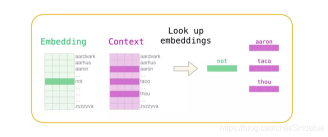
然后,我们计算输入嵌入与每个上下文嵌入的点积。在每种情况下,结果都将是表示输入和上下文嵌入的相似性的数字。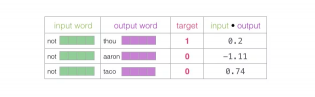
现在我们需要一种方法将这些分数转化为看起来像概率的东西——我们需要它们都是正值,并且 处于0到1之间。sigmoid这一逻辑函数转换正适合用来做这样的事情啦。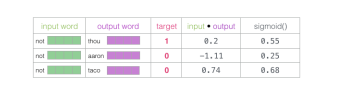
现在我们可以将sigmoid操作的输出视为这些示例的模型输出。您可以看到taco得分最高,aaron最低,无论是sigmoid操作之前还是之后。
既然未经训练的模型已做出预测,而且我们确实拥有真实目标标签来作对比,那么让我们计算模型预测中的误差吧。为此我们只需从目标标签中减去sigmoid分数。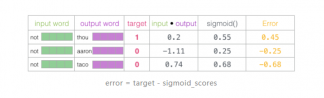
这是“机器学习”的“学习”部分。现在,我们可以利用这个错误分数来调整not、thou、aaron和taco的嵌入,使我们下一次做出这一计算时,结果会更接近目标分数。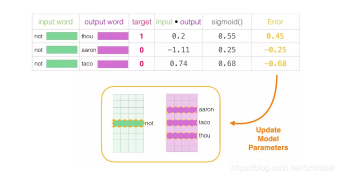
训练步骤到此结束。我们从中得到了这一步所使用词语更好一些的嵌入(not,thou,aaron和taco)。我们现在进行下一步(下一个相邻样本及其相关的非相邻样本),并再次执行相同的过程。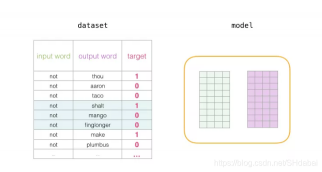
当我们循环遍历整个数据集多次时,嵌入会继续得到改进。然后我们就可以停止训练过程,丢弃Context矩阵,并使用Embeddings矩阵作为下一项任务的已被训练好的嵌入。
Window Size and Number of Negative Samples
word2vec训练过程中的两个关键超参数是窗口大小和负样本的数量。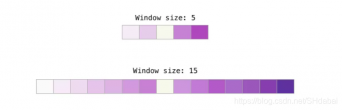
不同的任务适合不同的窗口大小。一种启发式方法是,使用较小的窗口大小(2-15)会得到这样的嵌入:两个嵌入之间的高相似性得分表明这些单词是可互换的(注意,如果我们只查看附近距离很近的单词,反义词通常可以互换——例如,好的和坏的经常出现在类似的语境中)。使用较大的窗口大小(15-50,甚至更多)会得到相似性更能指示单词相关性的嵌入。在实际操作中,你通常需要对嵌入过程提供指导以帮助读者得到相似的”语感“。Gensim默认窗口大小为5(除了输入字本身以外还包括输入字之前与之后的两个字)。
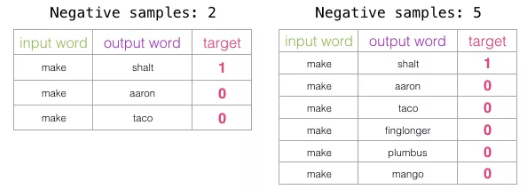
负样本的数量是训练训练过程的另一个因素。原始论文认为5-20个负样本是比较理想的数量。它还指出,当你拥有足够大的数据集时,2-5个似乎就已经足够了。Gensim默认为5个负样本。
结论:
我希望您现在对词嵌入和word2vec算法有所了解。我也希望现在当你读到一篇提到“带有负例采样的skipgram”(SGNS)的论文(如顶部的推荐系统论文)时,你已经对这些概念有了更好的认识。



评论(0)
您还未登录,请登录后发表或查看评论