

1.Scipy 简介
SciPy 是一个开源的 Python 算法库和数学工具包。
Scipy 是基于 Numpy 的科学计算库,用于数学、科学、工程学等领域,很多有一些高阶抽象和物理模型需要使用 Scipy。
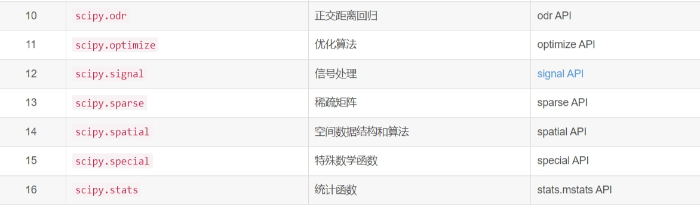
SciPy 包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。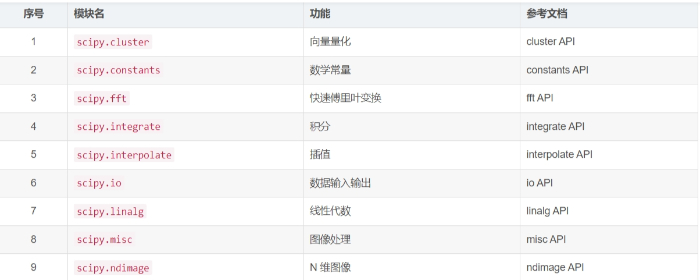
2. signal 模块
1. signal.butter()
巴特沃斯(Butterworth)数字和模拟滤波器设计。
设计一个 N 阶数字或模拟巴特沃斯(Butterworth)滤波器并返回滤波器系数。
语法:
scipy.signal.butter(N, Wn, btype=’low’, analog=False, output=’ba’, fs=None)
参数:
- N:int
滤波器的阶数。对于 “带通(bandpass)”和 “带阻(bandstop)”滤波器,最终二阶截面(‘sos’)矩阵的阶数为 2*N,N 为所需系统的二阶截面数。 - Wn:array_like
临界频率。对于低通和高通滤波器,Wn 是一个标量;对于带通和带阻滤波器,Wn 是一个长度为 2 的序列。
对于巴特沃斯滤波器,这是增益下降到通带的 1/sqrt(2) 的点(“-3 dB 点”)。
对于数字滤波器,如果未指定 fs,则 Wn 单位将从 0 归一为 1,其中 1 为奈奎斯特频率(因此 Wn 单位为半周期/采样,定义为 2* 临界频率/fs)。如果指定了 fs,则 Wn 的单位与 fs 相同。
对于模拟滤波器,Wn 是角频率(如 rad/s)。 - btype:{‘lowpass’, ‘highpass’, ‘bandpass’, ‘bandstop’}, optional
滤波器类型。默认是 ‘lowpass’. - analog:bool, optional
当为True时,返回模拟滤波器,否则返回数字滤波器。 - output:{‘ba’, ‘zpk’, ‘sos’}, optional
输出类型:分子/分母(‘ba’)、极点-零点(‘zpk’)或二阶截面(‘sos’)。默认为 “ba “是为了向后兼容,但 “sos “应用于通用滤波。 - fs:float, optional
数字系统的采样频率。
返回值:
- b, a:ndarray, ndarray
IIR 滤波器的分子(b)和分母(a)多项式。仅在 output=’ba’ 时返回。 - z, p, k:ndarray, ndarray, float
IIR 滤波器传递函数的零点、极点和系统增益。仅在 output=’zpk’ 时返回。 - sos:ndarray
IIR 滤波器的二阶截面表示法。仅在 output=’sos’ 时返回。
2. signal.filtfilt()
对信号正向和反向应用数字滤波器。
此函数将线性数字滤波器应用两次,一次向前,一次向后。合并后的滤波器相位为零,滤波器阶数是原滤波器的两倍。
该函数提供了处理信号边缘的选项。
在大多数滤波任务中,应优先使用 sosfiltfilt 函数(以及使用 output=’sos’ 的滤波器设计),而不是 filtfilt,因为二阶部分的数值问题较少。
语法:
scipy.signal.filtfilt(b, a, x, axis=-1, padtype=’odd’, padlen=None, method=’pad’, irlen=None)
参数:
- b:(N,) array_like
滤波器的分子系数向量。 - a:(N,) array_like
滤波器的分母系数向量。如果 a[0] 不等于 1,则 a 和 b 都被 a[0] 归一化。 - x:array_like
要滤波的数据数组。 - axis:int, optional
应用滤波器的 x 轴。默认值为-1。 - padtyp:estr or None, optional
必须为 “奇数”、“偶数”、”常数 “或 “无”。这决定了应用滤波器的填充信号所使用的扩展类型。如果 padtype 为 None,则不使用任何填充。默认为 “奇数”。 - padlen:int or None, optional
在应用滤波器之前,在轴线两端扩展 x 的元素个数。该值必须小于 x.shape[axis] - 1。padlen=0 表示无填充。默认值为 3 * max(len(a),len(b))。 - method:str, optional
决定处理信号边缘的方法,是 “pad “还是 “gust”。当方法为 “pad “时,信号将被填充;填充类型由 padtype 和 padlen 决定,irlen 将被忽略。方法为 “gust “时,使用 Gustafsson 方法,忽略 padtype 和 padlen。 - irlen:int or None, optional
方法为 “阵风 “时,irlen 指定滤波器脉冲响应的长度。如果 irlen 为空,则不会忽略脉冲响应的任何部分。对于长信号,指定 irlen 可以显著提高滤波器的性能。
返回值:
- y:ndarray
与 x 形状相同的滤波输出。
3. signal.find_peaks()
根据峰值属性查找信号内部的峰值。
该函数使用一个 1-D 数组,通过简单的相邻值比较找出所有局部最大值。此外,还可以通过指定峰值属性的条件来选择这些峰值的子集。
语法:
scipy.signal.find_peaks(x, height=None, threshold=None, distance=None, prominence=None, width=None, wlen=None, rel_height=0.5, plateau_size=None)
参数:
- b:(N,) array_like
- x:sequence
有峰值的信号。 - height:number or ndarray or sequence, optional
要求的峰高。可以是数字、无、匹配 x 的数组或前者的 2 元素序列。第一个元素始终被解释为最小高度,第二个元素(如果提供)被解释为最大高度。 - threshold:number or ndarray or sequence, optional
所需的峰值阈值,与其相邻样本的垂直距离。可以是数字、无、与 x 匹配的数组或前者的 2 元素序列。第一个元素始终被解释为最小阈值,第二个元素(如果提供)被解释为最大阈值。 - distance:number, optional
相邻峰之间所需的最小水平距离(>= 1)。先移除较小的峰,直到所有剩余峰都满足条件为止。 - prominence:number or ndarray or sequence, optional
所需的峰值突出度。可以是数字、无、与 x 匹配的数组或前者的 2 元素序列。第一个元素始终被解释为最小突出度,第二个元素(如果提供)被解释为最大突出度。 - width:number or ndarray or sequence, optional
要求的样本峰宽度。可以是数字、无、匹配 x 的数组或前者的 2 元素序列。第一个元素始终被解释为最小宽度,第二个元素(如果提供)被解释为最大宽度。 - wlen:int, optional
用于计算峰的突出度,因此只有在提供了突出度或宽度参数时才会使用。有关其作用的详细说明,请参见 peak_prominences 中的参数 wlen。 - rel_height:float, optional
用于计算峰值宽度,因此只有在给出 width 时才会使用。关于参数 rel_height 的作用,请参阅 peak_widths 中的参数 rel_height。 - plateau_size:number or ndarray or sequence, optional
所需的样本峰平顶尺寸。可以是数字、无、与 x 匹配的数组或前者的 2 元素序列。第一个元素始终被解释为最小值,第二个元素(如果提供)被解释为所需的最大平顶尺寸。
返回值:
- peaks:ndarray
x 中满足所有给定条件的峰的指标。 - properties:dict
包含返回峰属性的字典,这些属性是在评估指定条件时作为中间结果计算出来的
Ref.
")


评论(0)
您还未登录,请登录后发表或查看评论