前言: 本篇博客加入了PID调控,基于黑线对于图像中线位置的偏移量与黑线的角度进行的上位机PID调参,输出的是电机的目标转速。传给下位机左进一步处理。(今晚上先放上代码,明天再继续更新) PID简述: 广义上的PID可以分为数字式PID和模糊式PID,这里我对数字式PID进行了简单的学习,本篇文章也主要是对数字式PID的一个讲解。 用一句
#!/usr/bin/env python3 # 识别的是中线为白色 import cv2 import numpy as np # center定义 center = 320 # 打开摄像头,图像尺寸640*480(长*高),opencv存储值为480*640(行*列) cap = cv2.VideoCapture(0) while (1): ret,
膨胀一般用来填补物体中小的空洞和狭窄的缝隙,使物体的尺寸增大。 膨胀运算需要生成结构内核才能完成,在HALCON中使用gen_circle来生成圆形结构内核,这个函数的参数中:(1)第一个参数Circle为输出的圆形结构区域;(2)第二个参数Row为输入圆形区域中心行坐标;(3)第三个参数是Column为输入圆形区域中心列坐标。 使用gen_rectangle1来生成矩形结构内核,这个函数的参
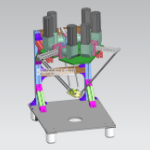
前言: 本篇文章是前两篇文章的进阶版本(基于python-opencv实时识别黑线赛道(一)与基于python-opencv实时识别黑线赛道(二)),在实时识别黑线的基础上标注了黑线的角度,同时,本篇文章也是作为使用树莓派作为上位机调节PID的第一步。后续内容将与我的博客(从零开始制作STM32F103RCT6小车系列)有联系。 本篇博客是基于如图所示的小车的体
文章目录 前言 一、deeplabV3+ 二、数据准备 三、修改代码 四、开始训练 五、测试 前言 在上一篇主要了解了语义分割,实例分割,全景分割的区别,以及labelme标注的数据进行转换,这边文章主要是通过deeplabV3+ 构建自己的语义分割平台 一、deeplabV3+ 上图所示,是deeplabV3+的主体框架,简单来说就是编码,解码的过
Linux下基于GTK人脸识别界面设计 1.人脸识别简介 人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术。用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部识别的一系列相关技术,通常也叫做人像识别、面部识别。 人脸识别系统的研究始于20世纪60年代,80年代后随着计算机技术和光学成像技术的发展得到提高,而真正进入初级的应用
打开Halcon,点击摄像头图标,打开设置窗口,接口选择DirectShow 连接选项卡中点击“实时”按钮,可以在主界面中看到摄像头采集的画面 最后点代码生成按钮,采集单幅图像,异步,插入代码,即可看到主界面有代码生成 在图像窗口上点右键,工具,灰度直方图,打开直方图窗口 点RGB选择2号通道,也就是绿色通道,会变成单色显示 将界面最左边的绿色竖线往右拉,比如
文章目录: 1 人脸添加口罩masked_faces 2 添加口罩原理 3 添加口罩代码操作 4 源码分析 A realistic approach to generate masked faces applied on two novel masked face recognition data sets 1 人脸添加口罩masked_faces 1、论文和代码 pape
最邻近插值算法 1. 算法简介 各种插值算法以及图像相关基础知识介绍在笔者之前的博客《CV学习笔记-数字图像概述》中已经详细介绍,在此仅作简单介绍:最邻近插值The nearest interpolation 设i+u, j+v (i, j为正整数, u, v为大于零小于1的小数,下同)为待求象素坐标,则待求象素灰度的值 f(i+u, j+v) 如下图所示: 简而言之,就是在放大图像时
好久没有更新博客了,最近在学习深度学习、机器学习部分的内容,有好的方法和经验想要在这里分享给大家。 (A)首先,用户使用熟悉类似Pytorch的语法指定神经网络结构,并使用熟悉类似Pytorch的语法进行编码,参数被传递给每一个层,指定各种信息,如卷积特征图的数量、激活函数等。该模型被添加到场景中,可以渲染为一个单一的禁止帧; (B)然后用户可以指定一个他们下午用代码播放的动
在上一篇【Originbot探索发现③】AprilTag探索 中,从AprilTag码入手,分析了AprilTag码工具包的安装使用,主要原理以及标定原理,本节将继续探索,首先针对Originbot小车的相机进行标定,然后去通过AprilTag码获取平面的法向量。 1. 获取Originbot相机内参 具体操作步骤: 首先下载一个棋盘格的图打印下来,我这里提供一个 棋盘格.pdf
在上一篇【Originbot探索发现②】自动回冲方案探索 中,分析了自动回冲对位的几种可行方案,最后依靠纯视觉对位的方案成为首选方案,本篇就继续探索视觉对位方案,先从AprilTag码入手 1. AprilTag码小试 1.1 安装工具包 Windows下: pip install pupil-apriltags Ubuntu下: pip install april
前言: 本文为手把手教学树莓派4B项目——YOLOv5-Lite目标检测,本次项目采用树莓派4B(Cortex-A72)作为核心 CPU 进行部署。该篇博客算是深度学习理论的初步实战,选择的网络模型为 YOLOv5 模型的变种 YOLOv5-Lite 模型。YOLOv5-Lite 与 YOLOv5 相比虽然牺牲了部分网络模型精度,但是缺极大的提升了模型的推理速度,该模型属性将更适合实战部署使用。
============================================================================================== ============================================================================================== opencv3
背景: colmap下进行三维重建可以利用最小割将图片分块,局部进行重建,利用分布式可以加速此流程。 最小割简单示意: s为起点,t为终点,阻断s到t的流量的代价最小的割的集合,叫做最小割。 normalized N cut 带权重的最小割,因为实际graph中没有s和t,如果只想把整个graph切成两部分,就可能出现下图min-cut 1和min-cut 2。 引入norm
前言 这段时间在和学弟打软件杯的比赛,有项任务就是机器人的视觉巡线,这虽然不是什么稀奇的事情,但是对于一开始不了解视觉的我来说可以说是很懵了,所以现在就想着和大家分享一下,来看看是如何基于opencv来实现巡线的。我这里以ubuntu20.04为例了 正文 1.查看相机设备 首先要完成视觉巡线那必不可少的就是相机了,使用 ll /dev/video* 来查看相机。 这里可以看到我
更新:对于特征匹配和三维重建的影响,下列所有因素都只是量变,根本因素是拼接和裁剪造成的各种畸变,后续会把新实验结果放上来。 稀疏重建中,航空倾斜摄影效果较好,主要源于视角统一,高空俯瞰。星型网状的拓扑结构,源于跨航带跨图片的远距离关联性与较好的回环检测。 而街景较为单一,地面视角,朝左和朝右并不能重叠。采用绕圈对向采集,利用去程的左和返程的右视角额外补充匹配效果,不过景深变化过大,
描述 背景:曲面重建技术在数据可视化、机器视觉、虚拟现实等领域中有着广泛应用。例如在汽车、航空等工业领域,一些复杂外形产品的设计仍需要根据手工模型,利用逆向工程的手段建立产品的数字模型;在医学和定制生产领域,可以根据测量数据去建立人体等计算机模型;除此之外RGBD相机在娱乐领域,也让人们开始用点云去处理对象。 定义:曲面重建技术是将点云数据转换为三角网格模型的过程。它是计算机视
1.项目介绍 项目为点钞机或者硬币计数器,实验使用卢比(印度)硬币作为测试对象,系统可实时检测到硬币面值。如果放置5卢比,它显示由0变成了5卢比,如果投入1卢比,它变成了6,如果再投入2卢比,它变成了8。所以系统主要区分三种不同面值硬币(5,2,1)。系统使用不同的技术去区分它,如果我们继续添加,它会继续的添加到总数中,不会得到错误的结果,可见该系统运行非常稳定。如果去掉5卢比,它会由34变
摘要 1 概述 2 目标检测回顾 2.1 two-stage 2.2 one-stage 3 目标检测配方 3.1 基础概念 3.1.1 损失函数 3.1.2 Anchor-based 和 Keypoint-based 3.1.3 NMS 3.2 目标检测中的挑战 4 目标检测中的Head 4.1 ThunderNet 4.2 You Only Look Once(YOL
第三方账号登入
看不清?点击更换



























第三方账号登入
QQ 微博 微信